第4名方案:多任务学习、半监督学习与集成
我们撰写了一份关于我们方案的技术报告,发布后您可以查看详细内容。在这里,我想简要描述一下我们的解决方案。我们的得分是公开榜 0.752(第3名)/ 私有榜 0.75787(待定前第4名)。
在这次比赛中,我们主要使用了3种策略:
- 带有噪声标签的多任务学习。
- 带有噪声数据的半监督学习(SSL)。
- 对不同时间窗口训练的模型进行平均。
模型
- 使用 log-mel 频谱图的 ResNet34。
- 使用波形图的 EnvNet-v2。
预处理
- 128 mels
- 128 Hz (347 STFT hop size)
Log-mel 在应用所有增强后从功率转换为分贝。此后,通过每个数据的均值和标准差进行归一化。
数据增强
Log-mel
- 切片
- MixUp
- 频率掩蔽
- 增益增强
我们尝试了 2、4 和 8 秒(256、512 和 1024 维度)作为切片长度,4 秒得分最高。调整大小、变形、时间掩蔽和白噪声不起作用。
- 附加切片
期望更强的增强效果,在基本切片之后,我们将数据样本缩短到基本切片长度的 25 - 100% 范围内,并通过零填充扩展到基本切片长度。
波形
- 切片
- MixUp
- 增益增强
- 缩放增强
我们尝试了 1.51、3.02 和 4.54 秒(66,650、133,300 和 200,000 维度)作为切片长度,4.54 秒得分最高。
训练
ResNet
- Adam
- 循环余弦退火 (1e-3 -> 1e-6)
- Sigmoid 和二元交叉熵
EnvNet
- SGD
- 循环余弦退火 (1e-1 -> 1e-6)
- (Sigmoid 和二元交叉熵) 或 (SoftMax 和 KL 散度)
后处理
使用完整长度音频输入的预测比使用切片 TTA 的预测得分更高。这可能是因为分类的重要成分集中在音频样本的开头部分。实际上,开头部分的切片预测比后半部分的切片预测得分更高。我们发现填充增强是有效的 TTA 方法。这是一种将零填充应用于音频样本两侧并具有不同长度,然后平均预测结果的增强方法。我们认为这种方法具有强调音频样本开始和结束部分的效果。
多任务学习
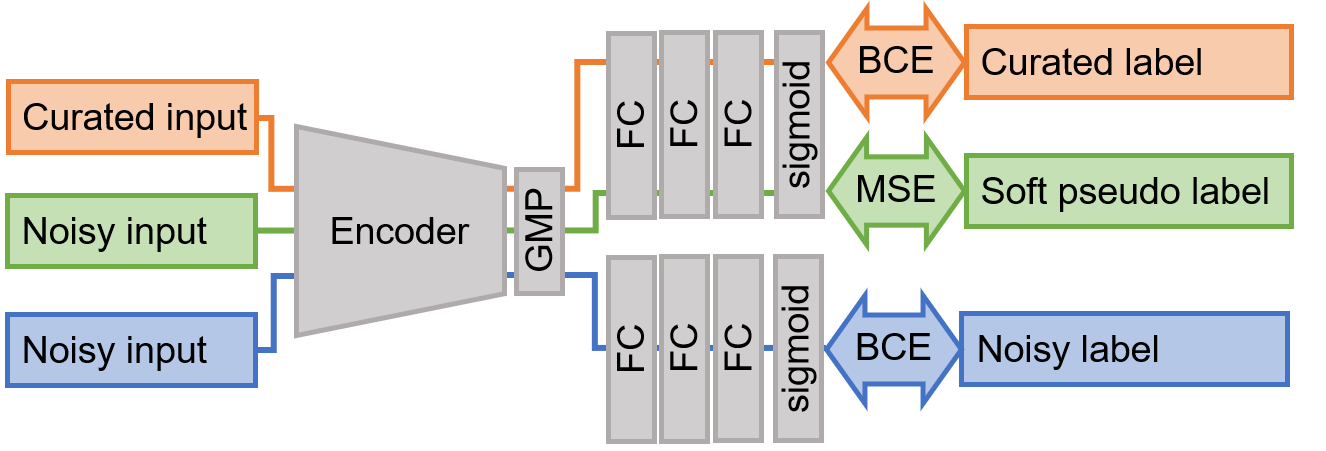
在这个任务中,精选数据和噪声数据的标记方式不同,因此将它们视为同一种数据会降低模型性能。为了解决这个问题,我们使用了多任务学习(MTL)方法。MTL 的目的是在不降低每个任务性能的情况下,在两个任务之间获得协同效应。MTL 学习两个任务之间共享的特征,并且可以期望比独立学习获得更高的性能。在我们的提议中,编码器架构学习精选数据和噪声数据之间共享的特征,两个分离的全连接(FC)层学习两个数据之间的差异。这样,我们可以获得从噪声数据中学习特征的优势,并避免噪声标签扰动的劣势。
多任务模块组件:
FC(1024)-ReLU-DropOut(0.2)-FC(1024)-ReLU-DropOut(0.1)-FC(80)-sigmoid
我们使用 BCE 作为损失函数。精选数据和噪声数据的损失权重比设为 1:1。通过这种方法,CV lwlrap 从 0.829 提高到 0.849