Freesound 第7名解决方案
感谢所有的参赛者、Kaggle团队以及本次比赛的主办方!我们在比赛中享受了很多乐趣,也学到了很多东西。
我们要特别感谢 @daisukelab 提供的清晰指导以及优秀的 Kernel 和数据集,感谢 @mhiro2 分享的优秀训练框架,以及 @sailorwei 在他的公开 Kernel 中展示的 Inception v3 模型。
我们团队的解决方案与其他团队的不同之处在于以下几点。
关键点: 数据增强、强度自适应裁剪、自定义 CNN (Custom CNN)、随机缩放裁剪
详细的解释在以下的 Kernel 中,请阅读它。
https://www.kaggle.com/hidehisaarai1213/freesound-7th-place-solution
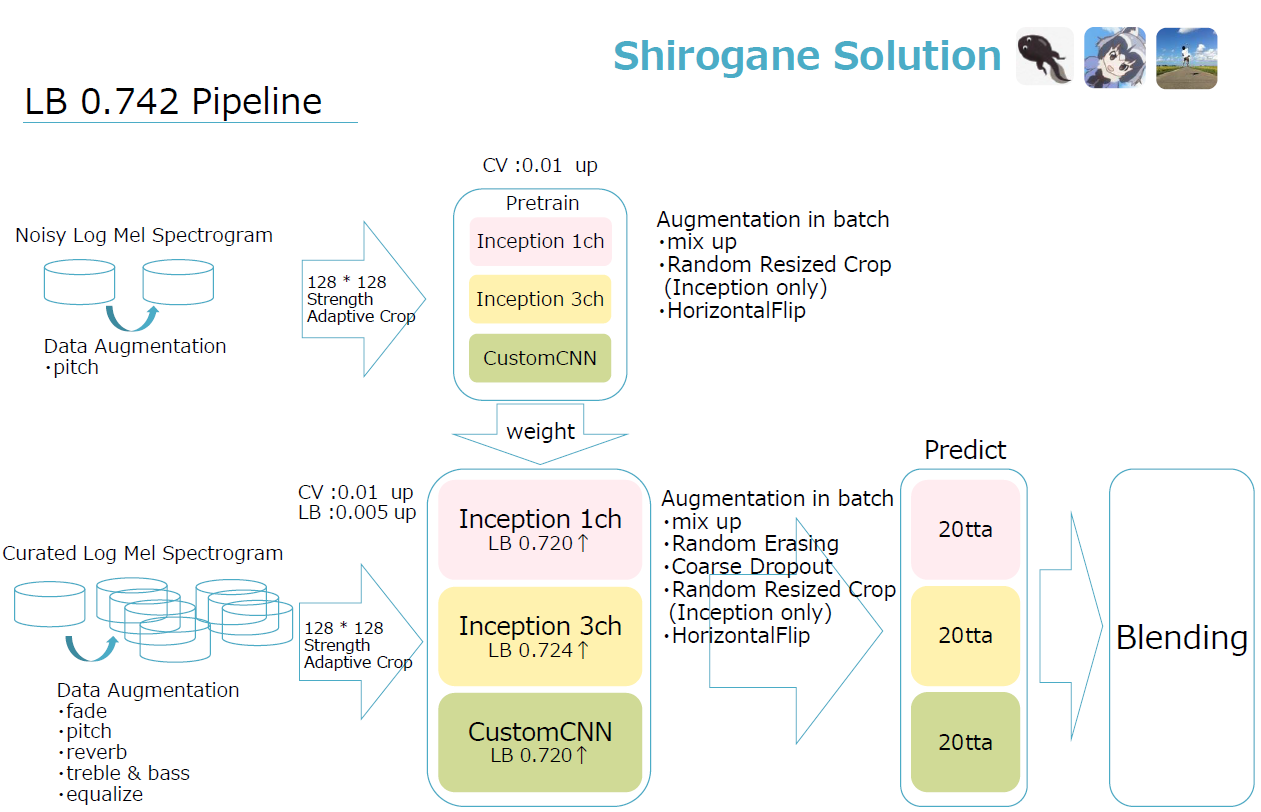
数据增强
我们使用 sox 创建了7个增强的训练数据集。
- fade (淡入淡出)
- pitch * 2 (音调变换)
- reverb (混响)
- treble & bass * 2 (高音 & 低音)
- equalize (均衡器)
我们在排除泄露数据后,总共训练了 4970 * 8 个样本。
裁剪策略
我们使用随机裁剪,因为我们使用固定的图像大小 (128 * 128)。随机裁剪的交叉验证得分比裁剪前2秒的方法略好。起初,我们是像 mhiro 的 Kernel 那样进行均匀裁剪的。
强度自适应裁剪
许多声音片段的重要信息位于前几秒。有些样本的重要信息位于片段中间。然而,由于录音的性质,声音末尾包含重要信息的情况很少见。当仅学习最后几秒时,分数下降了约 0.03~0.04。
因此,我们引入了 强度自适应裁剪。我们尝试优先裁剪总分贝较高的区域。
这种方法非常有效,因为大多数样本在声音较大的地方包含重要信息。
CV 提升 0.01
LB 提升 0.004~0.005
详细代码在 这个 Kernel 中。
模型结构
- InceptionV3 3通道
- InceptionV3 1通道
- CustomCNN (自定义CNN)
CustomCNN 是根据声音特征精心设计的。详情请见 这个 Kernel。
批次内增强
- Random erasing 或 Coarse Dropout (随机擦除或粗粒度Dropout)
- Horizontal Flip (水平翻转)
- mixup
- Random Resized Crop (随机缩放裁剪,仅用于 InceptionV3)
训练策略
验证集 TTA
当使用 RandomResizedCrop 时,验证分数会波动,如果不使用验证集 TTA,就无法选择合适的 epoch。因此,我们对验证集使用了 TTA,以确保可以正确评估验证结果。
第一阶段:使用噪声数据进行预训练
我们使用噪声数据来“预训练”我们的模型。LB 提升约 0.01。
第二阶段:使用精选数据训练 1
我们使用精选数据来“微调”那些用噪声数据“预训练”过的模型。
第三阶段:使用精选数据训练 2 (仅 Inception)
我们使用第二阶段的最佳权重进行第三阶段训练,但不使用随机缩放裁剪。虽然不知道原因,但在 Inception 模型中不使用随机缩放裁剪时,lwlrap 分数会上升。