feiyun组斩获冠军!RAG多步精细化比对策略,破解金融长文本矛盾检测难题

AFAC2026
在小说阅读器中沉浸阅读

feiyun组在AFAC总决赛
路演现场进行答辩
本团队获得AFAC2025大赛挑战组赛题二:金融保险场景下多源文件长上下文一致性校验一等奖。
获奖团队介绍
我们团队成员分别是来自上海交通大学和西安交通大学的学生,尽管研究方向不同,但都对大模型在真实场景下的应用有着浓厚兴趣。在本次比赛中,我们团队通过不断探索多种方案和对算法的多轮迭代,最终成功构建了一套文档一致性检验的方案,并取得了优异的成绩。
获奖寄语
在此,感谢AFAC大赛为我们提供了丰富的数据和前沿的应用场景,感谢赛事组给我们提供了一个能够学以致用和展示交流的平台!
赛题背景
本赛题聚焦于保险产品售卖素材的长文本、多素材内容一致性智能核验,要求参赛者基于保险产品的相关素材及检验规则,检验不同文档间是否有针对该规则存在矛盾的情况。评估指标为 F1-score。
方案综述
我们团队构建了一个 RAG 驱动的多步内容检测模型,旨在高效、准确地识别金融长文本中的矛盾。该方案主要分为三个阶段:内容检索、基于 LLM 的文本比对、精排与后处理。整个系统框架流程图如下所示:
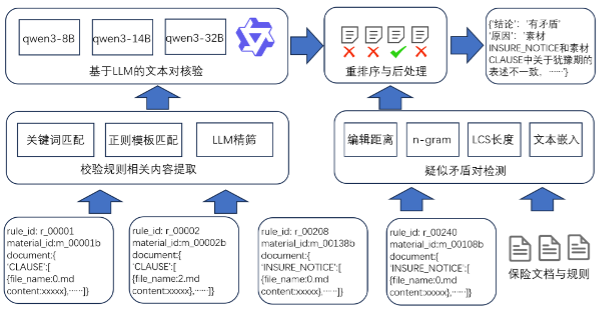
解决方案详解
1 内容检索:高效提取关键信息
内容检索的核心目标是从大规模、长上下文文本中精确提取与待检验规则高度相关的文本内容。我们分析了原始文档的长度分布(如下图所示),面对保险材料规模庞大(部分文档近百万字)和自然语言不确定性的挑战,我们团队设计了一种结合 LLM 和语法规则的检索算法。首先,我们利用语法规则过滤掉 95% 与校验规则无关的内容。随后,使用 LLM 对初筛的少量内容进行语义精筛,以获取真正相关的文本。
- 切片处理: 将材料按标点符号、分隔符、条款标号进行切片。
- 基于关键词的方法: 根据校验规则检测切片中是否包含相关关键词,例如 “条款名称” 、“注册号” 等。
- 基于文本模板匹配的方法: 利用正则表达式构建匹配模板,匹配特定文本格式。例如,针对 “保障相关时间” 使用正则表达式 “数字”+“时间单位” 的格式,并考虑中文汉字和阿拉伯数字的差异。
提取出和待检验规则相关的切片后,我们会使用大模型进行 json 结构化数据的提取,并用相似性算法(如 LCS、embedding 向量相似性等)找出有可能存在矛盾的切片对。考虑到领域内文本的特殊性,我们最终选择了最长公共子序列(LCS)算法,因为它不仅能找到相似文本对,还能揭示差异字符,为 LLM 的后续检验提供更多信息。为了提高效率,先使用 n-gram 相似性指标快速过滤掉相似度低的文本对。提取阶段的具体案例如下:


2 LLM文本比对:深度语义分析
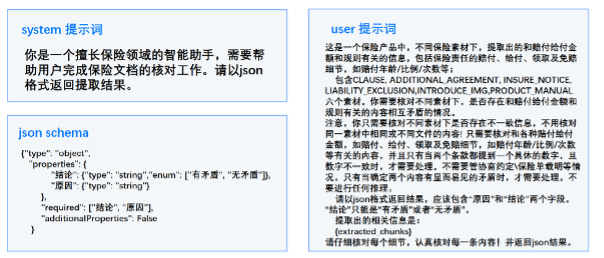
在获得相关内容切片和疑似矛盾文本对后,我们团队利用 LLM 进行深度检验。针对直接输入超长内容导致漏检率高和误检同一素材下文本对的问题,我们设计了组间文本匹配算法,将切片分为若干组,每次向 LLM 提供两个组的切片,显著提升了 LLM 的指令遵循能力。
为了确保结果的结构化输出,我们团队设计了基于 json schema 的 json 校验和自动重试功能,有效解决了 LLM 生成结果语法错误或不符合设定的问题。具体案例如下:
3 精排与后处理:过滤假阳性矛盾对
后处理阶段旨在过滤掉 LLM 比对阶段误检出的假阳性矛盾对。我们团队最终采用了基于规则的后处理方案。例如,对于免责条款,团队观察到矛盾通常只涉及单条内容的缺失或表述矛盾,若存在多条内容矛盾,则可能对应不同条款的免责部分。因此,要求 LLM 输出不一致的数量,并仅在数量等于 1 时才认定为矛盾。我们还尝试给 LLM 提供工具调用能力,给 LLM 提供包括上下文查询在内种工具,利用 LLM 的内容理解能力和 prompt 设计进行过滤。
(1)技术创新与优化
我们团队在 LLM 应用方面进行了多项创新和优化,以提升方案的效率和准确性。主要创新点包括:
- LLM Workflow 调试与结构化数据流构建:团队以 LLM workflow 为核心,对开源 LLM 的选型、数据流的结构化构建和 prompt 的构造进行了深入优化。设计了一套各工作流的输入输出标准,并通过 json schema 模板、schema 验证和错误重试确保了每个步骤都能产生标准结果。同时,对每一步骤 LLM 产生的中间结果进行缓存,以保证结果可复现性和快速调试。调用流程图如下所示:
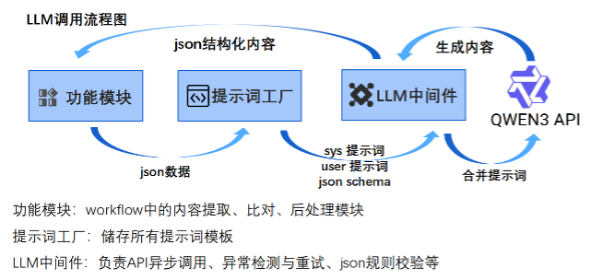
- 差异化 LLM 选型与异步调用:针对 LLM 推理速度瓶颈,团队采用了异步 LLM 调用的方案,通过设置信号量并发调用 Qwen API,将单条规则的匹配时间缩减至秒级,速度提升 7-10 倍。此外,团队构建了一套差异化的 LLM 选用方案,从不同参数规模的 Qwen3 开源版模型中选择,平衡生成质量和成本,在精度基本不下降的前提下,降本增效 20%~30%。
- “格式化输出 + 规则检查” 代替 “提示词硬性要求”:针对 LLM 在处理 “只检测不同素材中的矛盾对,不检测同一素材中的内容” 时,容易误检同一素材中内容的问题,团队不再通过提示词硬性要求,而是要求 LLM 输出矛盾内容所属素材,再通过规则代码判断两个来源素材是否相同,从而实现过滤。这一方法彻底解决了该问题,大幅增强了模型的指令遵循能力。
产业应用前景
本方案可广泛应用于保险行业下的自动化材料核验场景。通过构建基于内容检索和大模型比对的自动化核验系统,本方案可高效进行多源长文档的一致性校验,显著提高核验效率,减少人工核验带来的高成本和漏检等问题。该系统通过内容提取组件和并行化大模型调用,大幅降低了调用大模型比对的成本,提高了比对效率,单个材料的核验可在3分钟内完成。
此外,本方案不仅能判断材料是否有矛盾,而且可以输出矛盾对应的原文内容和矛盾原因,具有良好的可解释性。这一特性使其不再是一个黑盒工具,而是可以为人工审核员提供可靠、透明的决策支持,尤其适用于对准确性有严苛要求的场景,能极大减轻其工作负担,使其专注于更复杂的价值判断。
总结与展望
本方案通过结合高效的内容检索、多层次文本比对和 LLM 驱动的结构化风险检测,有效提升了保险文档一致性校验的自动化与准确率,兼顾效率和准确性,大幅降低了人工成本和出错率。

feiyun队在AFAC总决赛路演现场领奖(左三)

—END—