ths队获得二等奖!超长上下文冲突检测系统,推理耗时短、落地简单

在小说阅读器中沉浸阅读

ths队在AFAC总决赛路演现场进行答辩
本团队在赛题二:金融保险场景下多源文件长上下文一致性校验 中获得二等奖。
获奖团队介绍
- 谭守东:ths队队长,毕业于北理工大学,现就职于同花顺
- 钱美娟:ths队队员,毕业于北化工大学,现就职于新和成
团队获奖经历丰富,从2020年开始组队打比赛,已参与几十场赛事,同时也是第二次参与AFAC大赛。
解题思路
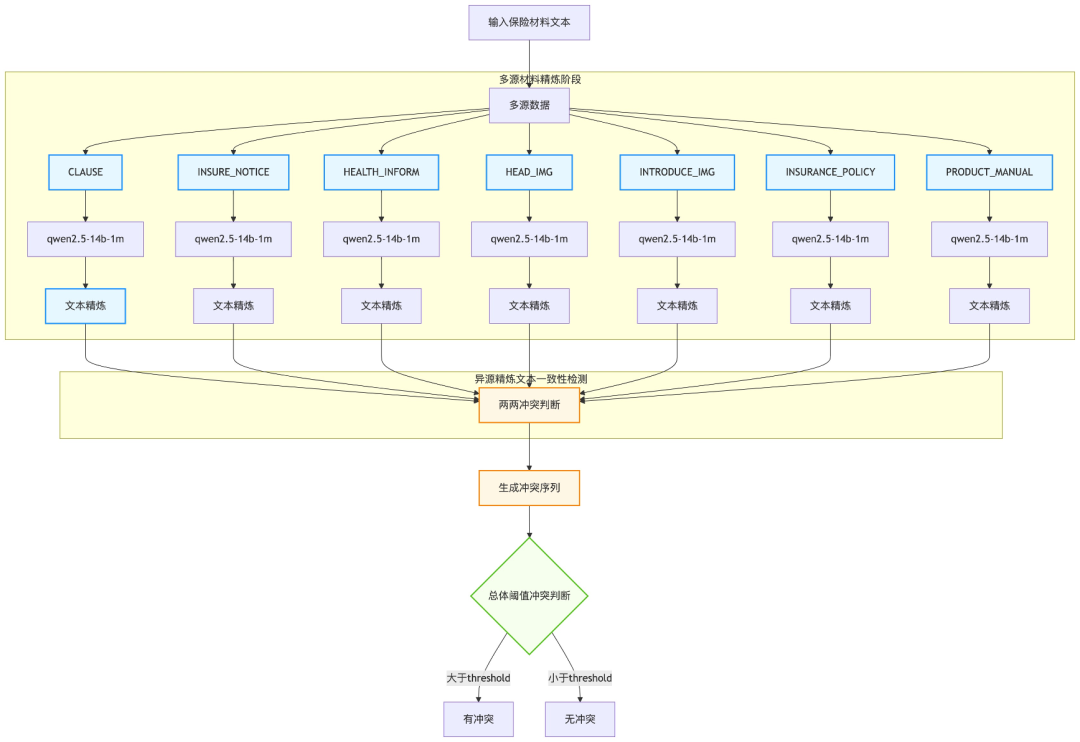
在金融保险行业中,电子保单、保险条款、营销物料等素材的合规性与一致性关乎业务的稳健发展。当前,行业普遍依赖人工核验多源文件内容,存在两大痛点:一是效率瓶颈,长文档(如条款文本、免责声明)的逐项比对耗时耗力;二是动态规则适配难,随着经济发展,保险市场环境也在不断变化,同时,保险产品类目众多,产品迭代频繁,这种动态性为合规校验系统提出了更高的要求。基于这种情况,我们提出了方案:基于llm的超长上下文冲突检测系统。
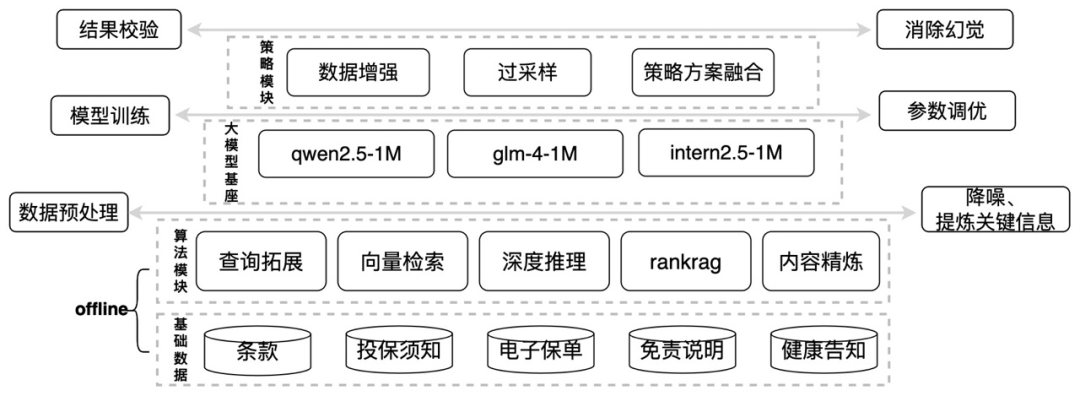
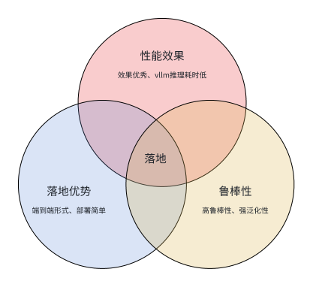
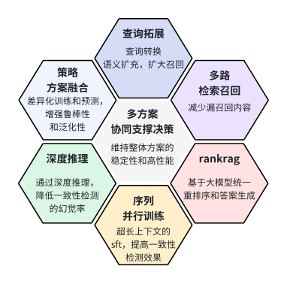
基于llm的超长上下文冲突检测系统是一个端到端的冲突检测方案,方案整体是由多个子方案和模块构成。这些子方案和模块从不同视角(数据、算法、校验等)为大模型提供了多个维度的辅助信息,帮助大模型进行特征训练和合规性、一致性的冲突检测。整体方案榜单效果优秀,推理耗时短、落地简单,具有可推广性。
解决框架
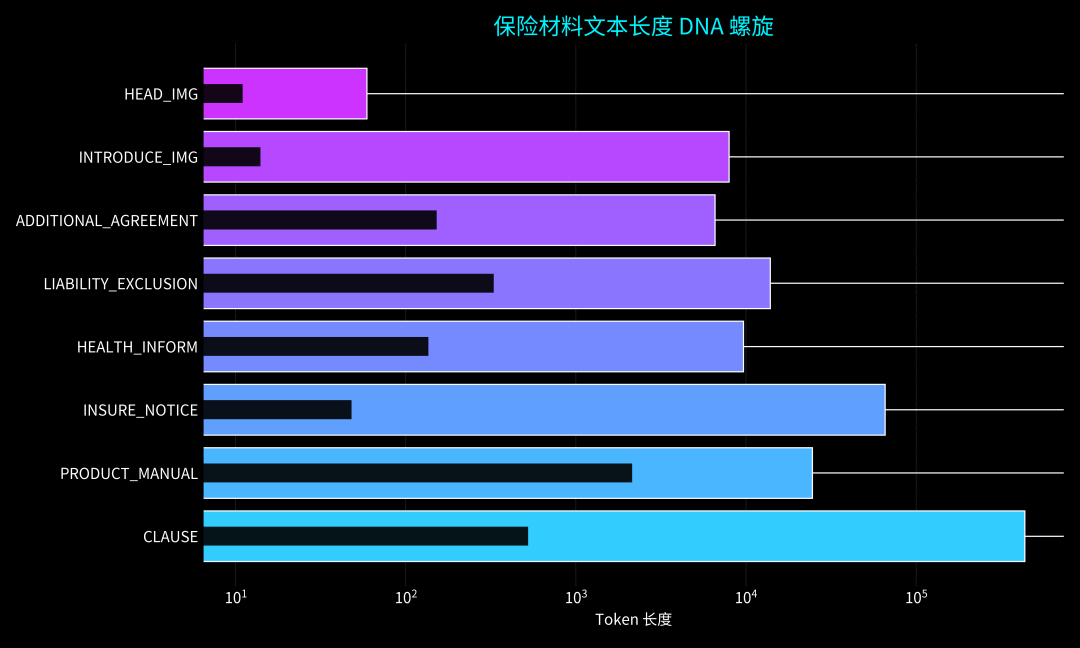
金融保险场景下多源文件长上下文一致性校验赛道的主要任务是校验保险产品不同类型材料(而非同类型材料,同类型材料可能存在冲突)关于某个规则是否存在定义冲突的情况,通过数据分析我们发现,每个类型材料的文本长度在几千到几十万之间,长度差异非常大。
我们基于官方提供的baseline方案进行了优化,baseline 方案在进行片段分割时有严重缺陷,语义不对齐,并且没有解决同类型材料可能存在冲突问题。基于此,我们尝试了多种优化方案(基于rag问答的校验方案、基于超长上下文的问答校验方案和基于伪标签数据进行sft的校验方案),结合数据增强、过采样、层次化决策的等技术策略,获得了a榜rank2、b榜rank2的优秀成绩。
要点解析
数据分析
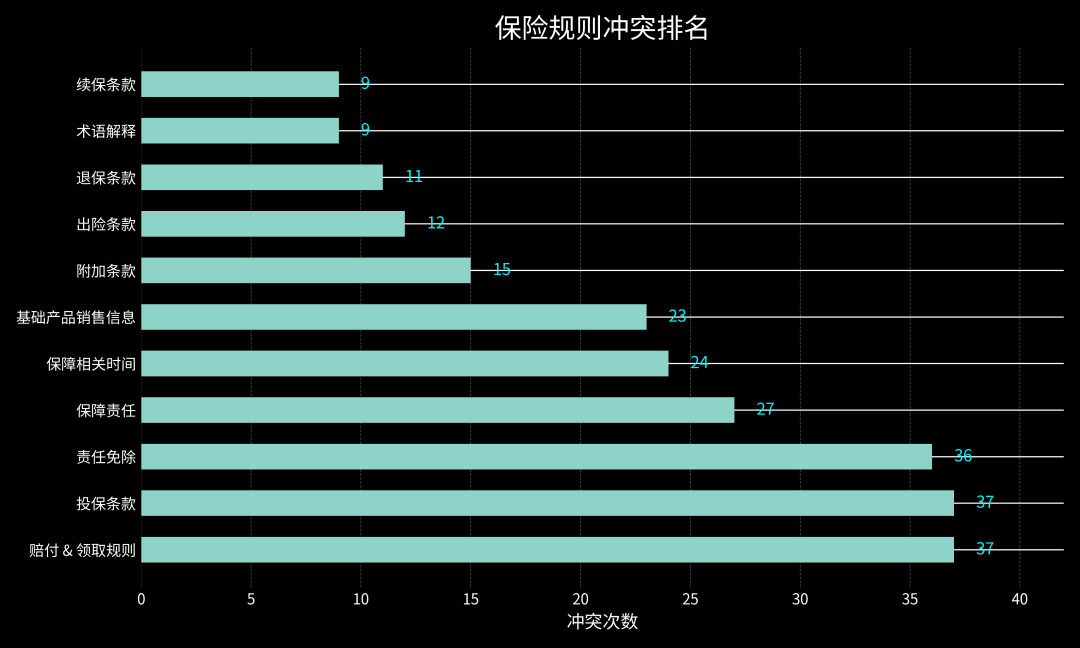
根据统计,每个材料类型的文本长度在几千到几十万之间,长度差异不可谓不大。且部分规则较为模糊,例如术语解释。
明确任务
校验每个保险产品的不同类型材料(而非同类型材料,同类型材料可能存在冲突)关于某个规则是否存在定义冲突的情况。
算法实现
方案一(baseline)
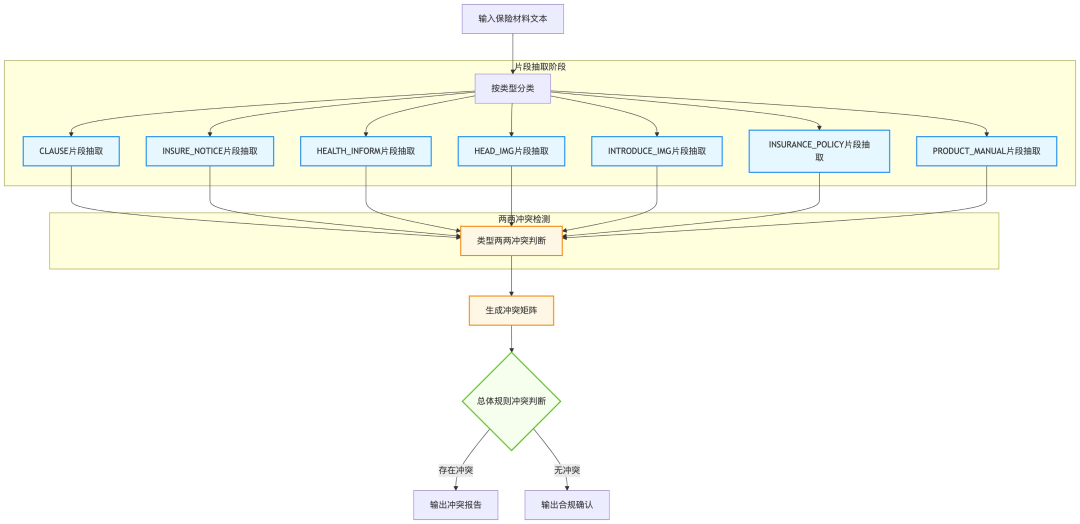
核心思想步骤
- 先对每个类型的材料分段(以句号分割),再利用大模型对每段文本进行相关片段的抽取(与校验规则相关的);
- 基于不同类型材料抽取出的相关片段,依次两两判断是否存在校验规则的冲突(二分类),只有所有二分类都不存在冲突,则该产品关于某校验规则的定义不存在冲突。
效果
实际效果挺差的,a榜低于0.7,并且模型越大,效果越差。
存在的问题
- 片段分割方案有严重缺陷,语义不对齐;
- 没有解决同类型材料可能存在冲突问题
基于以上问题,提出了方案二。
方案二(基于rag问答的校验方案)
核心思想步骤
- 基于校验规则进行查询拓展(产品保障责任>>产品保障范围、产品保险金额、产品增值服务);
- 然后基于查询拓展后的每个问句进行检索(使用bge模型构建的向量索引),召回相关chunk;
- 基于不同类型材料抽取出的相关chunk,依次两两判断是否存在校验规则的冲突(二分类),只有所有二分类都不存在冲突,则该产品关于某校验规则的定义不存在冲突。
效果
相比方案一,效果提升15个百分点,a榜得分80。
存在的问题
检索召回时存在漏召回情况,对后续冲突检验判断误导性较大。
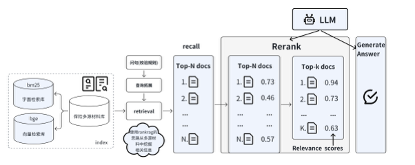
方案三(基于超长上下文的问答校验方案)
根据统计,每个材料类型的文本长度在几千到几十万之间,普通的大模型的上下文长度在128k,难以容纳全部上下文,于是采用1M的模型,最长可支持百万token的上下文输入。
核心思想步骤
- 以问答形式,使用1M模型(qwen2.5-14B-1M),得到某个类型的材料关于校验规则的回答内容;
- 基于不同类型材料得到的关于校验规则的答案,依次两两判断是否存在校验规则的冲突(二分类),只有所有二分类都不存在冲突,则该产品关于某校验规则的定义不存在冲突。
效果
相比方案二,效果提升5个百分点,a榜得分85+。
存在的问题
基于不同材料之间的两两校验结果来决定整体校验结果的方案存在一定的局限性。
方案四(基于伪标签数据进行sft的校验方案)
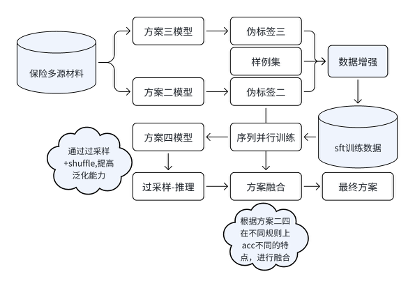
前面三个方案,本质上都是基于不同材料之间的两两校验结果来决定整体校验结果,方案四跳开这个框架,从全局视角来进行规则校验:
核心思想步骤
- 基于方案三中a榜得分85+的结果文件,构建伪标签训练数据,结合官方提供样例数据,进行数据增强,构建1100条训练数据,用于sft的训练;
- 使用流水线并行技术进行sft训练,训练结束后,预测时进行过采样,得到多个预测结果进行投票得到最终预测结果。
场景应用
我们的方案:基于llm的超长上下文冲突检测系统,方案整体是由多个子方案和模块构成,可以根据场景类型和需求的不同,灵活的选择不同的子方案进行落地,具有效果优秀、响应耗时低和鲁棒性强等特点。

ths队在AFAC总决赛路演现场领奖(右五)
转发有礼
- 关注 "AFAC2025"公众号。
- 转发本篇文章到朋友圈+5个技术微信群(100人以上),并截图发到 【AFAC2025】 公众号后台。
- 先到先得,AFAC公众号后台会私信中奖者提供收货信息。

—END—
