三步升级baseline|如何高效优化金融多模态报告生成智能体

本团队在AFAC大赛挑战组赛题四:金融多模态报告生成智能体中获得三等奖。
获奖团队介绍:
- 石尚轩:西安电子科技大学在读,研究方向为脉冲神经网络
- 郭子亨:天津大学在读,研究方向为数据可视化
- 欧阳宇萌:中国传媒大学在读,研究方向为智能媒体
方案简介
方案代码repo:Mouseminar/financial_research_report: 金融研报生成demo
本方案主要是基于官方baseline进行改进的,这个文章写的特别详细特别好!!!所以在读本文章之前,请先阅读官方的方案。本方案就是站在巨人肩膀上,对大佬方案的改进优化~
具体改进主要是在:搜索引擎和研报生成这两个部分。
接下来我会先分析官方的baseline有哪些不足,然后再讲一下我们的改进思路和方案。
搜索引擎改进
1 baseline的搜索方案不足之处
baseline方案如下图所示:决策LLM会先根据当前的章节标题生成一组关键词交给搜索引擎,然后搜索引擎返回搜索结果再交给决策LLM进行判断当前搜集的内容是否充足,如果充足就生成当前的章节,不充足再继续搜索。
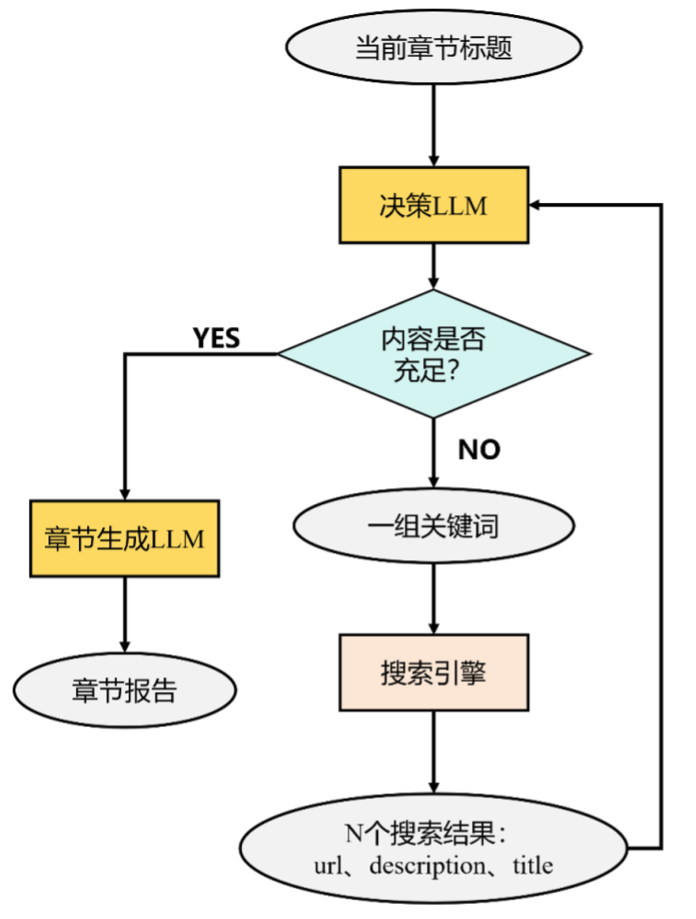
我们发现这个workflow主要存在三个不足:
- 搜索出来的结果只有title和description,没有去解析正文。下图是从搜索结果中选取的一个例子,他没有解析正文,信息严重不足。就好比我们在网上搜东西,只看标题和简介,却没有点开文章去读具体内容,这显然是不够的。

- 搜索出的内容相关性弱 / 噪声高。下图举了一个搜索结果的例子。红框中明显不是我们想要的结果。我们使用搜索引擎搜索的时候,返回给我们的结果中存在大量的无关信息。如果把所有未筛选的信息交给LLM使用,上下文爆炸不说,还会导致模型无法聚焦关键信息。

- 缺少一个“删除机制”,无法主动剔除无关信息。即使发现搜索到的内容是无效的,Baseline的方案还是会把它直接写入上下文,没有清理机制。这就会导致上下文知识被污染,低质量信息越积越多,无效的上下文越来越长,最后的生成结果也会越来越差。
那么针对这三个问题呢,我们分别提出了针对的解决方案,下面来看一下整体的改进方案~
2 整体改进方案
针对问题一,我们引入了更高效的“搜索引擎+ 网络爬虫”,不仅可以获取标题和简介,还能深入解析网页正文。针对问题二,我们在搜索引擎和网络爬虫中间加入了一个筛选模型,来根据标题初步过滤掉无关信息。针对问题三,我们引入了一个“知识库”,让决策模型主动删除知识库中的低质内容,保证知识库纯净。
我们的整体改进思路是借鉴现代搜索引擎的“召回—粗排—精排”的多阶段检索机制,建立了“召回—初筛—自过滤”的检索pipeline,从而显著提高了收集到信息的质量。
下图展示了我们的整体改进方案:
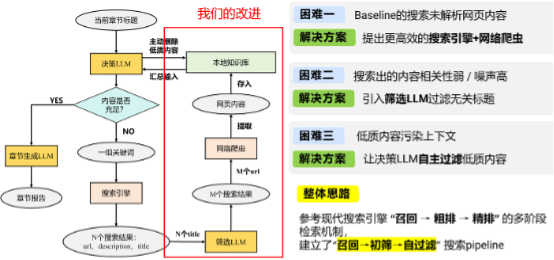
更高效的搜索引擎+网络爬虫
搜索引擎负责根据关键词找到相关网页url,网络爬虫负责抓取网页url的内容。
1 多引擎自动回退机制
首先,本次比赛要求我们只能使用免费的搜索引擎来获取信息。baseline中使用的是sogou和ddg,可以选择使用其中一个。但是当长时间使用同一个搜索引擎的时候,会触发人家的反爬机制,让搜索引擎失效,这好吗?这不好。所以我们的想法也很简单,直接多来几个搜索引擎(sogou、ddg、bing)交替工作,一个挂了另一个给我上!
search_engine.py的对应代码:
def search(self, keywords: str, max_results: int = 10) -> List[Dict[str, Any]]:
"""
统一搜索接口,按照 Sogou -> DuckDuckGo -> Bing 的顺序回退
Args:
keywords: 搜索关键词
max_results: 最大结果数
Returns:
搜索结果列表,每个结果包含 title, url, description 字段
"""
print(f"[搜索🔍] 开始搜索: '{keywords}'")
# 按顺序尝试搜索引擎
search_engines = ["sogou", "ddg", "bing"]
if self.engine != "sogou":
# 如果初始化时指定了其他引擎,将其放在第一位
search_engines = [self.engine] + [e for e in search_engines if e != self.engine]
for engine in search_engines:
try:
print(f"[搜索🔍] 尝试使用 {engine.upper()} 搜索引擎")
if engine == "ddg":
results = self._search_ddg(keywords, max_results)
elif engine == "sogou":
if not SOGOU_AVAILABLE:
print("❗Sogou 搜索不可用,跳过")
continue
results = self._search_sogou(keywords, max_results)
elif engine == "bing":
results = self._search_bing(keywords, max_results)
else:
continue
if results:
# 过滤已缓存的结果
new_results = self._filter_cached_results(results)
print(f"[{engine.upper()}] 搜索成功!原始结果: {len(results)} 条,新结果: {len(new_results)} 条")
time.sleep(random.uniform(*self.delay))
return new_results
else:
print(f"❗{engine.upper()} 无结果或被拦截,尝试下一个搜索引擎")
except Exception as e:
print(f"❗{engine.upper()} 搜索失败: {e}")
continue
print("❗所有搜索引擎都失败了")
return []经过我们的测试,发现引入多引擎自动回退机制还是很有效滴,基本上不会出现搜索中断的问题了。
2 url哈希缓存机制避免重复请求
我们来考虑一个问题,决策LLM在生成关键词的时候,每一个关键词其实都是互相有关联的,所以使用这些关键词去搜索到的网页难免会出现重复现象。而且在我们引入多引擎的时候,搜索到网页重复的现象更加剧了(因为当前引擎并不会记得上一个引擎搜到了什么,只会使用当前的关键词继续搜索,很容易搜到重复的网页)。所以一个自然而然的思想就是,我们把每次搜到的url的hash值缓存起来,如果搜到重复的网页自动去重即可。
search_engine.py的代码如下:
def _filter_cached_results(self, results: List[Dict[str, Any]]) -> List[Dict[str, Any]]:
"""过滤已缓存的结果,返回新结果并更新缓存"""
new_results = []
cache_updated = False
for result in results:
url = result.get('url', '')
if not url or url == '无链接':
continue
url_hash = self._get_url_hash(url)
# 检查是否已缓存
if url_hash in self.url_cache:
print(f"[Sogou🐶] 跳过已缓存的URL: {url[:50]}...")
continue
# 添加到缓存
self.url_cache[url_hash] = {
'url': url,
'title': result.get('title', '无标题'),
'description': result.get('description', '无摘要'),
'cached_time': time.time()
}
new_results.append(result)
cache_updated = True
# 保存缓存
if cache_updated:
self._save_cache()
return new_results这个方法也挺有效的,尤其是到了搜索的后期阶段,能够过滤掉很多重复的url。
3 网络爬虫
网络爬虫的代码在url_handler.py里,我们把这一块添加进来,用来解析url抓取正文。就是常见的网络爬虫技术,这里就不细讲了。
加入筛选LLM过滤无关标题
我们发现搜索引擎搜到的结果又多又杂,把这么多的未经筛选的结果直接交给网络爬虫爬取并存入知识库中,开销会很大。所以我们想,搜索引擎的结果正好包含标题,我们能不能先根据标题把那些一眼无关的网页给过滤掉呢。
这里我们使用了一个LLM来完成这个任务,具体做法如下:在prompt中先说明当前的章节主题,然后把所有的标题组合成一个list并标好序号,让LLM直接把不相关的序号告我们,然后我们下来主动删除这些标题对应的信息。
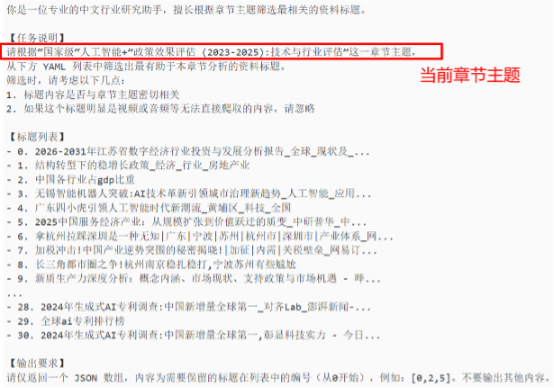
代码如下:
class FilterTitles(Node):
"""基于 LLM 对 SearchInfo 拿到的结果按标题做过滤"""
def __init__(self):
super().__init__()
def prep(self, shared: dict):
"""
输入:
shared["current_section"]["name"] —— 本章标题
shared["context"](由 SearchInfo.post 放入)——列表格式,每个元素是 {'term': ..., 'results': [...]}
返回:
sec_name, flat_items:
flat_items 是 [{'title': ..., 'url': ...}, ...] 扁平化列表
"""
themes = shared.get("industry", "行业研究")
sec_name = shared["current_section"]["name"]
flat = []
for block in shared.get("context", []):
for item in block["results"]:
flat.append({"title": item["title"], "url": item["url"]})
return themes, sec_name, flat
def exec(self, inputs) -> List[Dict]:
# 直接call LLM
themes, sec_name, flat = inputs
titles = yaml.dump(flat, allow_unicode=True)
# 只需要title,然后编号
titles = "\n".join(f"- {i}. {it['title']}" for i, it in enumerate(flat))
prompt = FILTER_TITLES_PROMPT.format(
industry_name=themes,
section_name=sec_name,
titles=titles
)
# 保存prompt到本地
# 统计当前章节的过滤次数,用于文件名唯一性
safe_sec_name = sec_name.replace(' ', '_').replace('/', '_').replace('\\', '_')
if not hasattr(self, "_filter_count"):
self._filter_count = {}
self._filter_count[safe_sec_name] = self._filter_count.get(safe_sec_name, 0) + 1
prompt_file = f"./macro_outputs/prompts/filter_titles_prompt_{safe_sec_name}_{self._filter_count[safe_sec_name]}.txt"
with open(prompt_file, 'w', encoding='utf-8') as f:
f.write(prompt)
logger.info(f"[FilterTitles] Saved prompt for section '{sec_name}' → {prompt_file}")
resp_text = call_llm(prompt).strip()
logger.info(f"[FilterTitles] LLM response: {resp_text}")
# print(f"LLM 响应:{resp_text}")
# 从 resp_text 中抽取 JSON 数组
import re, json
m = re.search(r"\[.*\]", resp_text, re.S)
try:
idxs = json.loads(m.group(0)) if m else []
except Exception:
idxs = []
# 根据 idxs 过滤
filtered = [flat[i] for i in idxs if 0 <= i < len(flat)]
return filtered
def post(self, shared, prep_res, exec_res):
# 过滤后直接覆盖 shared["context"]
shared["context"] = exec_res
return None结果还是很有效的,至少能够过滤掉50%以上的无关标题,给后续节省了很大的开销。
让决策LLM自主过滤低质内容
baseline的方案是把搜索到的所有信息全部扔给决策LLM,就算明明是垃圾信息,却依然保留,没有主动清理垃圾信息的机制!所以我们要让决策的LLM在判断内容是否充足的同时,主动审查知识库。
这里的知识库是我们新建立的(baseline的方案只是暴力地把所有信息添加到上下文里面),用来高效有序地存储我们搜集到的信息。
我们改进了决策LLM的prompt(具体的prompt可以在代码里面看):
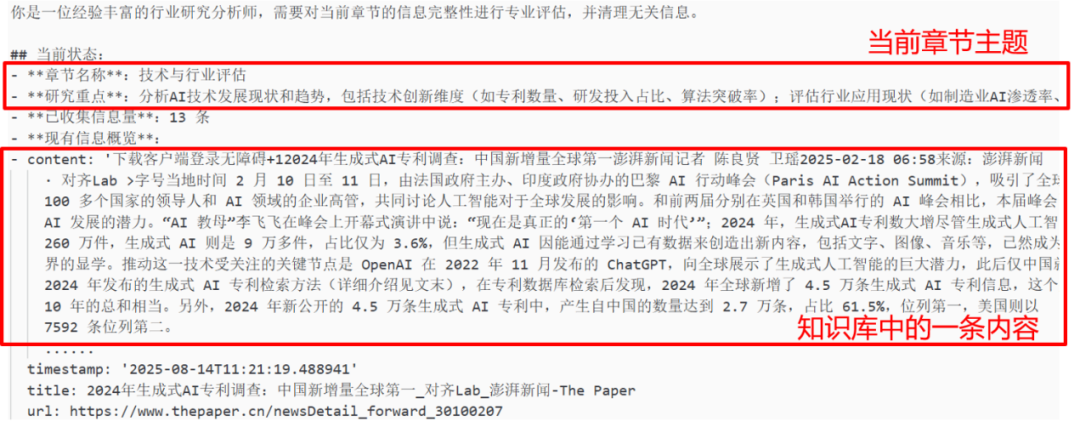

那么这样决策模型就能主动地删除它认为不需要的信息了,还能缓解大量信息导致的长上下文的问题。
研报生成改进
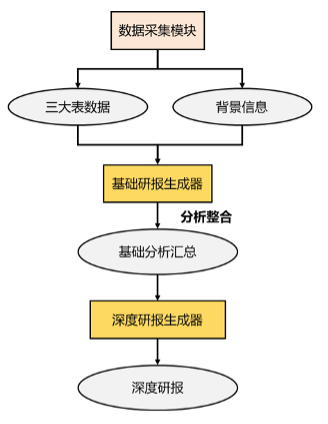
1 baseline的方案不足之处
baseline方案如下图所示:可以看到它是一个按部就班的workflow,它无法实现动态迭代分析。另外在可视化环节,存在一些图表误用和解释错误。
2 整体改进方案
我们针对Baseline 的三个问题分别做了改进。针对前两个问题,我们引入了监管式优化流程,通过“生成—评审—修改”的循环,实现动态迭代,让研报内容更加连贯和深入。针对第三个问题,我们提出了“数据检查”可视化,在生成图表分析的同时校验数据来源,进一步做出量化分析,保证图文一致。
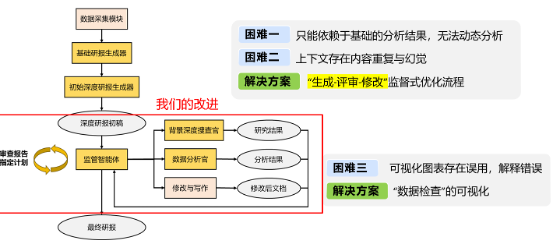
3 改进一:“生成-评审-修改”监督式优化流程
company/company_research_report_generator.py 这部分代码比较长,就不放出来了。
我们设置了不同角色的智能体。背景搜查官负责找背景信息,它可以主动去调用我刚才讲过的搜索引擎。数据分析官负责数据分析与可视化,然后再进行修改写作。这套流程让研报从“一次性输出”变成了“多轮优化”,大大增强了内容的质量和可控性。
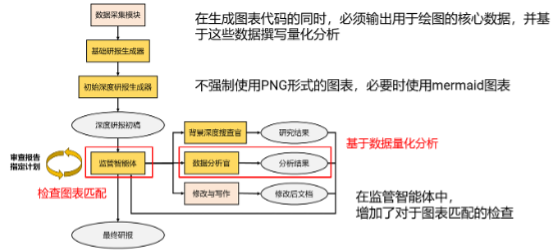
4 改进二:数据检查可视化
针对Baseline里图表容易误用、解释错误的问题,我们在生成图表代码的同时,输出绘图核心数据,并基于这些数据做量化分析;还有就是增加了mermaid图表以及图表匹配的校验。我们让图表不仅能“画出来”,更要能“对得上”。
总结与后续思路
我们的方案其实也没有特别大的创新,总体来说还是在对baseline做了一些改进。感谢主办方提供了完整的baseline方案,以及细节十足的讲解(在大佬肩上真好~)。
然后说一下后续思路:
- 扩展数据来源。我们希望不仅能抓取网页文本,还能解析网页中的多种文件格式,比如CSV、PDF,从而获取更丰富的数据。
- 增强泛化性。采用分治的思想建立起从详细大纲到并行扩充的多agents协作流。同时建立共享知识库,避免重复计算。
- 成本控制。对一些简单任务,可以用小模型来完成,比如微调一个 BERT 来筛选标题,从而降低整体运行成本。

好想成为人类队在AFAC总决赛路演现场领奖(左二)
转发有礼
1、关注 “AFAC2025”公众号。
2、转发本篇文章到朋友圈+5个技术微信群(100人以上),并截图发到 【AFAC2025】 公众号后台。
3、先到先得,AFAC公众号后台会私信中奖者提供收货信息。

—END—