深度方案解析|如何通过智能体协同工作流实现金融多模态报告的高效生成
在小说阅读器中沉浸阅读
天池三轮车队在AFAC总决赛路演现场进行答辩
本团队在赛题四:智能体赋能的金融多模态报告自动化生成 中获得三等奖。
队名叫"天池三轮车"是因为我们觉得三轮车比较稳定,无惧道路崎岖。
获奖寄语:
在金融领域,专业研究报告的撰写一直是高度依赖人工的复杂工作,需要分析师整合海量数据、分析市场趋势并形成专业见解。随着多模态大模型技术的快速发展,自动化生成金融研究报告正成为可能。本文将详细解析我们的技术方案,重点介绍如何通过智能体协同工作流实现金融多模态报告的高效生成。
整体架构设计:工作流驱动的生成范式
我们的方案主要通过WorkFlow来实现流程控制,将复杂的研报生成过程分解为有序的任务序列。选择工作流是因为我们认为这样最为清晰明了,且拆解之后的任务执行稳定,不会出现逻辑上太大的波动,上下文关联也更好。任务执行流程图如下,其中虚线框内为暂未实现的部分:
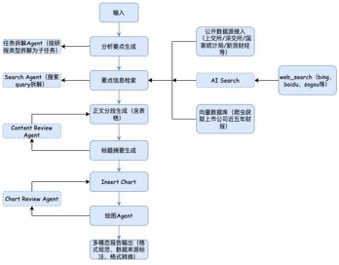
以公司研报生成为例,我们在输入一个公司名称之后,会先用模型生成一份研报的目录,包含每个段落的小标题和该段落的内容主旨;然后是取数环节,这里采用的是接口+RAG+WEB_SEARCH的方式;然后分段去生成内容并拼接,这部分会让模型根据输入的数据,在合适的地方插入表格;接着我们把生成的内容输入给大模型,让大模型生成对应的标题和摘要,并且让模型把一些上下文语义不太连贯的地方调整一下,使之更加富有逻辑性;接着在拼接免责声明之后,调用绘图Agent生成一些研报常用的图例,并让模型插入到研报合适的位置中,至此,一篇研报便基本生成完毕。
核心技术实现
1. 数据获取
在一篇金融研报中,数据的重要性不言而喻,数据的准确性、时效性和丰富度等各个维度上缺一不可,经过讨论,我们采用的是数据接口+RAG+WEB_SEARCH的方式来获取数据。
接口获取:
由于赛制要求不得使用付费接口,因此我们使用的是东财和新浪财经的免费接口,主要获取的是三大财务报表和行情相关的一些数据,接口获取数据的特点是准确性和时效性比较有保证;
RAG:
考虑到接口获取的都是关系型格式的数据,缺乏其他种类的数据,而这部分数据对于研报生成又非常重要,因此我们从巨潮资讯爬取了近五年的上市公司财报数据,并清洗合并,按年份和市场类别(港股、A股)分类。将爬虫结果输出到Excel表中保存,使用bge的Embedding模型将其(公司名,财报名称,财报链接)向量化存储到阿里云的ES向量库中,使用的时候根据公司名称匹配最新财报,抽取相关章节信息供使用;
WEB_SEARCH:
增加网络检索主要是考虑到数据的丰富度和时效性,通过控制一定时间内的检索,可以获取到针对每个段落主题的大量资讯信息,使得内容能够更加全面丰富。
2. 大模型驱动的段落主旨生成
在刚拿到赛题的时候,我们设想的是找一篇现成的研报,让大模型提取研报框架之后,用这个框架去生成所需的研报,但是经过实践发现,如果用这样的方式会有两个比较严重的问题,其一是大模型会把模板研报中的数据用到生成的研报中,从而导致数据上的错误;其二是生成研报字数波动非常大,有时候几千字,有时候才几百个字,不符合一份合格研报的要求。在参考baseline的实现之后,我们经过一番讨论,决定在此基础上做优化,以下为各阶段的具体过程:
阶段一:结构化大纲生成
研报大纲生成的关键创新点在于:
- 引入竞对信息:公司研报大纲在prompt中嵌入竞对信息,经过对比发现生成大纲效果更好,更接近于真实机构研报;
- 生成多重title:通过生成多层次的目录title,使得覆盖内容更全面,后续的web_search也因此可以搜索到更多的信息。
阶段二:段落级内容生成
针对每个子章节,系统会根据L2级目录内容进行检索,并将获取到的数据和研报目录、背景信息、财报段落内容和提炼出的内容以及接口数据一并送入大模型,生成该段落的文本内容,这样既可以保证获取到充足的数据,也可以让生成的段落上下文衔接得更自然。
3. 图表的处理
图表生成由专门的Agent来完成,由于除了接口以外的数据均不能保证其稳定性和准确性,所以我们考虑的是仅就接口可以获取到的数据进行绘图。
经过对接口数据的调研后,我们发现公司财务数据从接口中获取是比较稳定的,而行业和宏观的数据相对来说并不一定稳定可获取,因此决定公司研报采用绘图+表格的方式来展现多模态部分的内容,而行业研报和宏观研报则主要使用表格的方式。
调用Agent绘图完成之后返回一个url,然后将生成的研报连同生成图例的名称一起传入大模型,让大模型决定在什么位置插入该图例,最后将markdown格式转成word就完成了研报的生成。
系统优化方向
由于时间关系,原先规划好的一些优化措施没能实施,加上事后复盘列出的点,现总结如下:
1. Planner Agent
在最初的阶段设置一个统筹全局的Planner Agent,将研报生成拆解开为一个个子任务,分配到对应的模块。
2. Search Agent
- 在搜索阶段将workflow的方式改为Search Agent,拆解分析要点为合适的搜索query进行deepresearch;
- 在web_search的基础上,增加AI_Search,提炼精简web_search输出的页面信息,过滤掉冗余信息,提升大模型处理效率。
3. ContentReview Agent & ChatReview Agent
报告Review模块增加Content Review和Chart Review两个Agent,对输出的内容重点评估。其核心质量维度:
- Content Review Agent:审查标题与内容贴切度、逻辑严谨性、常识准确性、计算正确性等。
- Chart Review Agent:审查图表数据准确性、图表与内容贴切度、图表表现形式等。
技术应用设想
券商自动化研报:
接入实时财经数据与企业财报,基于多模态大模型生成行业分析、个股评级和投资策略,缩短分析师70%以上的基础工作时间,服务于中小券商的长尾客户需求;
投研知识库构建:
通过事件抽取与逻辑推理,将非结构化数据转化为结构化知识图谱,辅助机构投研团队快速定位投资机会,同时需强化数据合规与模型可解释性,满足金融级应用要求。

天池三轮车队在AFAC总决赛路演现场领奖(右二)