第三名解决方案
本文由我发布,但这是与 @christofhenkel 和 @theoviel 的合作成果:NVBird 团队!
感谢大家参与这场有趣的比赛,恭喜获奖者!我们对获得第三名感到非常高兴,尽管我们以微小的差距错过了冠军。
概述
我们的流程总结如下。解决方案的关键在于使用未标记的声景(soundscapes)进行伪标签(pseudo labeling)和模型蒸馏(model distillation)。我们先用训练数据训练了一些模型,然后用它们预测未标记声景中 5 秒片段的标签。将这些预测标签添加到原始训练数据中,用于训练最终提交的一组新模型。
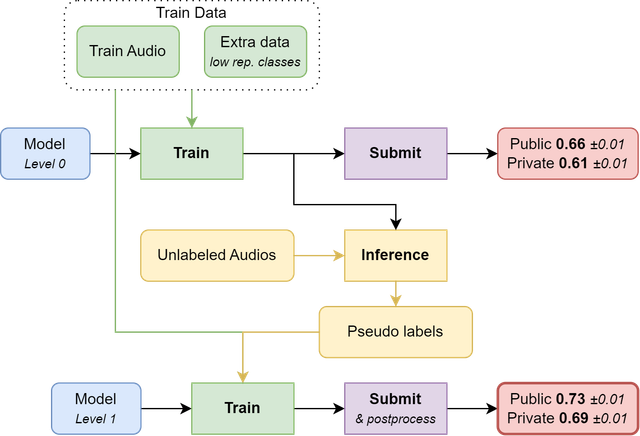
数据
总的来说,我们依赖于之前比赛获得的知识,并增加了一些额外样本以对抗类别不平衡。
我们使用了今年的比赛数据,加上论坛中分享的 Xeno Canto 额外数据,以及往年比赛中相同物种的记录。当某个记录名称出现在多个比赛中时,我们选择了最近的一个(因为它们的内容在不同比赛之间并不总是完全相同)。
我们将每个物种的记录数量上限设为 500 条,保留最近的记录。事实上,添加所有额外数据会导致严重的类别不平衡,从而损害模型准确性。
低频类别会被上采样,以确保每个类别在训练折中至少有 10 个样本。
为了训练模型,我们使用了以下预处理和增强方法:
我们没有使用所有的训练数据。对于每条记录,我们从记录的前 6 秒或后 6 秒中随机裁剪出 5 秒的片段。如果记录长度小于 5 秒,则进行随机填充,使得信号的中心位于 5 秒结果片段的 2 到 3 秒之间。对于大多数模型,除了 mixup 之外,我们只使用了窗口为一秒的时间移位(time shifting)作为增强。例外的是某些模型,它们 Inspired by Birdclef23 第二名 SED 模型 (链接) 并使用了那里相同的增强方法。
我们使用加法 mixup:主要标签是两个混合音频的主要标签的最大值。次要标签是次要标签的连接。
我们主要使用以对数梅尔频谱图(log mel spectrograms)作为输入的图像模型。对于这些模型,我们计算梅尔频谱图的参数 chosen 以产生 224x224 或 288x288 的图像大小,具体取决于我们使用的图像模型。输入波形被归一化为标准差为 1。
模型
第一级模型
仅 CPU 的要求对提交相当受限,但这不适用于伪标签生成,因此我们可以为第一级模型使用更多的骨干网络。当集成几个比第二级使用的模型更大的模型时,我们执行所谓的模型蒸馏。这通常是一种相当强大的技术。
使用的模型包括:
- Efficientvit_b0.224.in1k 在 224x224 对数梅尔频谱图上
- Efficientvit_b1.r288_in1k 在 288x288 对数梅尔频谱图上
- 各种 CNN(efficientnets, mobilenets, tinynets, mnasnets, mixnets)和 Efficientvits (b0, b1, m3) 在 224x224 对数梅尔频谱图上训练。
- SED 模型使用 tf_efficientnetv2_s_in21k 在 128x313 对数梅尔频谱图上
- 我们还微调了 aves-large 和 aves-base,这是一个最近的基于波形的模型。
根据流程的不同,使用这些模型中的一个或多个来预测未标记声景上的伪标签。我们大多数模型都在完整数据上用 5 个不同的种子进行了训练。
第二级模型
我们主要使用 efficientvit-b0 和 mnasnet-100 在 224x224 对数梅尔频谱图上。Efficientvit-b0 表现出很好的性能,同时推理速度非常快。使用 ONNX 提交 5 个折需要 40 分钟。我们尝试了几种与 effvit-b0 吞吐量相似的模型,决定也使用一个 mnasnet-100 以增加多样性。由于在 CPU 上计算对数梅尔频谱图很慢,我们决定在推理 notebook 中为所有模型使用相同的梅尔频谱图超参数,这样只需进行一次对数梅尔频谱图转换,并为我们的集成模型使用相同的输入。
为了训练第二级模型,我们将带有预测伪标签的未标记声景添加到训练数据中。这看起来很简单,但花了几次尝试才找到正确的方法。效果较好的是使用较大的批量大小(128)。
我们使用了以下两种策略:
- 向每个批次添加额外的声景。每个声景被分成 5 秒的片段,这意味着我们在每个批次的 128 个实际标签样本中添加了 48 x 4 = 192 个带有伪标签的片段。
- 添加 128 个带有伪标签的样本,这次取自随机声景。
最终集成
最后,我们通过 3 个流程集成了 14 个模型权重,每个团队成员一个流程:
流程 1 - 5 个种子
- Level 0: efficientvit_b0
- Level 1: efficientvit_b0
流程 2 - 2 个种子 + 2
- Level 0: efficientvit_b1, mobilenetv2, efficientnet_b0, efficientnetv2_b0, efficientvit_b0, efficientvit_m3, aves-base, aves-large
- Level 1: 2x mnasnet-100
- Level 0: Efficientvit_b0, mixnet_s, mnasnet_100, tinynet_b, efficientvit_b0, efficientvit_b1, mobilenetv3
- Level 1: 2x efficientvit_b0
流程 3 - 5 个种子
- Level 0: efficientvit_b1_288, 5x efficientnet_v2_s sed, aves-base, aves-large
- Level 1: 5x efficientvit_b0
该集成在私有排行榜得分为 0.689970,公有排行榜得分为 0.742124。
训练
在没有验证集的情况下调整参数有点棘手。我们有两个具有不同参数的训练流程,不太清楚到底是什么起了作用。
我们使用了 BCEWithLogitsLoss,没有任何标签平滑。标签由主要标签定义。次要标签用于掩码损失:次要标签的损失乘以 0。原因是我们不知道次要标签是否出现在记录的开头和结尾,但它们可能出现在那里。鉴于不确定性,我们掩码了这些损失。掩码次要标签损失使排行榜提高了约 0.01。
当在未标记声景上使用伪标签时,我们将它们的次要标签设置为空。
我们使用了 AdamW 或 Ranger 优化器。第二级的轮数(epochs)远高于第一级。例如,在一个流程中,第一级模型训练 30 个轮次,而第二级模型训练 88 个轮次。
后处理
我们使用了几种后处理方法,以结合声景级别的信息。
第一种方法最初在公有排行榜上效果很好,提升了 0.02。比赛结束后的实验表明,其效果要小得多(在我们最好的未选择提交上为 0.004),甚至在我们最好的选定提交上有害(- 0.002)。其想法是,如果一只鸟出现在声景的任何地方,那么它出现在任何 5 秒片段中的概率都会增加。
对于给定的声景,一旦我们有了 48x182 的 logits 数组或预测 P,我们计算 P 在时间维度上的最大值 P_max。然后我们将 P 替换为:
P + (P_max + P.mean() - P_max.mean()) * 0.8。
0.8 的权重可以进一步调整。
第二种后处理方法第一次尝试时对排行榜影响较小,但在我们最好的选定提交上影响较大,提升了 +0.01。其想法是通过将每个 5 秒片段与前两个和后两个片段稍微混合来平滑预测。我们使用卷积核 [0.1, 0.2, 0.4, 0.2, 0.1] 进行平滑预测。
无效的方法
很多。主要问题是我们找不到可靠的本地验证方案。我们主要像大多数参与者一样查看训练数据交叉验证,但也努力查看过去每年 BirdCLEF 训练/测试的差异。我们认为这可能有助于理解哪些增强方法可以弥合训练(= xeno-canto)/测试(= PAM 声景记录)之间的差距。然而,结果相当不确定。可能是因为每年的声景都很不同。无论我们尝试什么,一旦分数足够高,与公有排行榜的相关性就会丧失。
一件起初看起来效果很好但最终无效的事情是基于每个声景最大概率的后处理。
另一件是 Aves 模型,每次使用时公有排行榜提高约 0.01,但在私有排行榜上似乎有害。
我们尝试了许多增强方法,包括以前比赛或学术论文中记录的方法,但似乎都没有真正帮助。
ONNX 并没有带来太多的加速(可能 10%),而 Openvino 更快(与 pytorch 相比几乎 2 倍加速)。然而,我们注意到与 ONNX 相比,使用 Openvino 时下降了约 0.01,因此决定不使用它。也许 Openvino 的加速可以通过最终集成中使用更多模型来补偿?
我们最终的模型选择最终效果不太好。我们提交了一些私有分数高于 0.70 的单个模型,但鉴于它们的公有分数相对较低,我们没有将它们包含在集成中。
代码链接 (按字母顺序)
CPMP 的部分 https://github.com/jfpuget/birdclef-2024 Dieter 的部分 https://github.com/ChristofHenkel/kaggle-birdclef24-3rd-place-solution-dieter Theo 的部分 https://github.com/TheoViel/kaggle_birdclef2024 最佳选定提交 https://www.kaggle.com/cpmpml/birdclef-2024-inf-ens-08感谢阅读!