第四名解决方案:Team Cerberus
感谢 Kaggle、主办方以及所有的参赛者。参加这场激动人心的比赛是一次非凡的经历。以下是我们第四名解决方案的概览。这一成就确实是团队努力的结果,@ajobseeker 和 @tamotamo 做出了同等的贡献。我很感激有机会在这次比赛中与他们合作。
更新 (2024-06-23):
添加了推理 Notebook 和训练代码。
推理 Notebook: https://www.kaggle.com/code/yokuyama/bc24-4th-place/notebook
训练代码 (Melspec 模型): https://github.com/yoku001/BirdCLEF2024-4th-place-solution-melspec
训练代码 (原始信号模型): https://github.com/tamotamo17/BirdCLEF2024-4th-place-solution-raw-signal
概要 (TL;DR)
- Melspec 模型和信号模型的集成 (Ensemble)
- 测试时增强 (TTA)
- OpenVINO
- 后处理 (Post Processing)
分数
| 模型 | 公共分数 | 私有分数 | 公共分数 (+TTA) | 私有分数 (+TTA) |
|---|---|---|---|---|
| Melspec 模型 B (inception-next-nano) | 0.668 | 0.623 | ||
| Melspec 模型 A (rexnet_150) | 0.676 | 0.641 | 0.690 | 0.649 |
| Melspec 模型 A (seresnext26ts) | 0.682 | 0.645 | 0.693 | 0.651 |
| 原始信号模型 C (tf_efficientnet_b0_ns) | 0.673 | 0.620 | 0.691 | 0.636 |
| 加权平均 (Weighted Mean) | 0.717 | 0.667 | 0.731 | 0.676 |
| 加权平均 + 几何平均 | 0.732 | 0.677 | ||
| 加权平均 + 几何平均 + 平滑 | 0.741 | 0.685 | ||
| 加权平均 + 几何平均 + 平滑 + 截断 (最终提交) | 0.7469 | 0.6877 | ||
| 加权平均 + 几何平均 + 平滑 + 截断 + 与邻居取最大值 | 0.749 | 0.689 |
- 加权平均 (Weighted Mean)
0.15*模型 B + 0.25*模型 A (rexnet_150) + 0.3*模型 A (seresnext26ts) + 0.3*模型 C
- 几何平均 (Geometric Mean)
(0.15*模型 B + 0.25*模型 A (rexnet_150) + 0.3*模型 A (seresnext26ts) + 0.3*模型 C) + 0.3*(模型 A (rexnet_150) * 模型 C)**(0.5)- 通过将 MelSpec 模型 (模型 A) 和原始信号模型 (模型 C) 的几何平均添加到集成中,我们实现了分数的轻微提升。在最后选择这个集成使我们幸运地保持在获奖位置。
- 我们看到了很大的过拟合风险,所以决定不再花费更多时间调整集成权重。
模型 A: 2021-2nd Melspec CNNs
我们 heavily 参考了 2023 年第二名解决方案 的代码来构建此模型的训练和推理 pipeline。非常感谢 @honglihang 分享如此宝贵的信息。他们的代码库非常强大,经过少量修改,我们就能够创建一个 LB 分数为 0.68 的单一模型。
- 数据集
- BC2024
- 部分模型在 2021、2022 和 2023 年的数据集上进行了预训练。
- 训练时随机选取音频的 15-20 秒,验证时选取前 5 秒。
- 预处理
- n_mels=128, n_fft=2048, f_min=0, f_max=16000, hop_length=627, top_db=80.
- 数据增强
- 添加背景噪声 (datasets)
- 增益 (Gain)
- 噪声注入 (Noise Injection)
- 高斯噪声 (Gaussian Noise)
- 粉红噪声 (Pink Noise)
- Mixup
- 模型
seresnext26tsrexnet_150(2021-2023 预训练)
- 损失函数
- BCELoss
- 2023 年竞赛第一名 提出的类别采样权重。
模型 B: 简单 Melspec CNNs
- 数据集
- BC2024 + xeno-canto-additional-cleaned (见
验证策略部分) - 训练时随机选取音频的 5 秒,验证时选取前 5 秒。
- BC2024 + xeno-canto-additional-cleaned (见
- 数据增强
- 模型
inception-next-nano带注意力头 (attention head)- InceptionNeXt 具有与 ConvNeXt-nano 相同的缩放比例
from timm.models.inception_next import _create_inception_next from timm.models.inception_next import InceptionDWConv2d from timm.models._registry import register_model @register_model def inception_next_nano(pretrained=False, **kwargs): print("inception_next_nano") model_args = dict( depths=(2, 2, 8, 2), dims=(80, 160, 320, 640), token_mixers=InceptionDWConv2d, ) return _create_inception_next('inception_next_nano', pretrained=False, **dict(model_args, **kwargs))
模型 C: 原始信号 CNN
该模型 inspired by HMS 第二名解决方案。非常感谢 @cooolz!他们提供了 他们解决方案 的详细解释。
- 数据集
- BC2024
- 参考 此链接 移除了重复数据。
- 使用 xeno-canto 的数据为少数类添加了一些样本。
- 应用了按作者分组的分层 5 折交叉验证。
- 训练期间,样本少于 15 个的类别被上采样到 15 个样本。
- 预处理
- 使用每个音频样本的前 5 秒。
- 将音频下采样到原始速率的一半 (从 32000 Hz 到 16000 Hz)。
- 将下采样的音频数据从 80000 的大小重塑为 625x128。
- 数据增强
- 从未标记的数据中标注了 50 个背景片段,并作为背景噪声添加。
- 增益 (Gain)
- 噪声注入 (Noise Injection)
- 高斯噪声 (Gaussian Noise)
- 粉红噪声 (Pink Noise)
- 随机音量 (Random Volume)
- Mixup
- Cutmix
- 模型
tf_efficientnet_b0_ns带 SED 头
- 损失函数
- Focal Loss
验证策略
使用训练数据进行验证并没有给我们可靠的结果,所以我们转向了合成数据方法。
- 我们从 xeno-canto-additional 数据集中采样了 182 个类中的 40 个类的文件,并裁剪了鸟类发声的片段以创建干净的数据集。
- 我们从未标记的声音景观数据集中采样了仅包含背景噪声(没有鸟叫)的音频文件。
- 我们结合干净数据集和背景噪声,创建了一个带有时间序列标签的类测试数据集。
- 使用这个合成数据集,我们计算了 ROC AUC 分数。
虽然这种验证方法与 LB 结果并不完全相关,但与使用前 5 秒裁剪方法相比,它提供了更合理的结果。更多细节请参考 此 Notebook。
TTA (测试时增强)
为了提高时间序列预测的准确性,我们采用了类似于子像素超分辨率的技术。在推理期间,我们不仅预测 5 秒的帧,还预测了偏移 2.5 秒的帧。然后我们将这些结果组合作为 TTA。这种方法有助于完善整体预测。
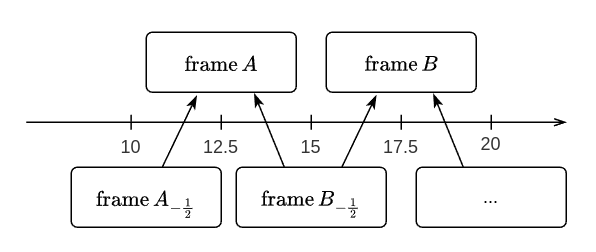
OpenVINO + INT8 训练后量化
为了加快模型的推理时间,我们使用了 OpenVINO。此外,我们实施了 训练后量化 将模型转换为 INT8。
对于量化校准数据集,我们使用了模型的训练数据集,应用了诸如添加背景噪声和增益变化等增强。我们相信这些增强将有助于创建更适合处理更广泛测试数据场景的量化模型。
结果令人印象深刻:我们的推理速度显著提高,量化模型的运行速度提高了30-40%。
在执行量化时,选择要量化的层至关重要。我们观察到,排除头层 (head layers) 的量化往往会提高模型的准确性。
names = ['/head/Gemm/WithoutBiases', '/global_pool/Pow', '/global_pool/GlobalAveragePool', '/global_pool/Pow_1', '/global_pool/Clip']
quantized_model = nncf.quantize(
model, calibration_dataset, subset_size=600,
ignored_scope=nncf.IgnoredScope(names=names),
)我们仅在提交截止日期前三天才开始进行量化工作,留给我们彻底验证集成和量化组合的时间不足。因此,我们在两次最终提交中仅在一次中使用了量化模型。(权衡:我们减少了此次提交的 TTA 运行次数。)
我们最终发现,启用量化并没有显著影响公共/私有分数。
后处理
通过使用几个技巧,我们能够在公共和私有榜单上将分数提高约 0.01。
- 平滑 (Smoothing)
- 类似于第 6 名团队,我们通过取相邻片段的移动平均来提高分数。
- 截断 (Cut-off)
- 在 4 分钟音频中出现一次的鸟类比其他音频更有可能再次出现。认识到由于噪声、与其他鸟类的重叠呼叫以及被 bin 边界切割的推理切片,概率可能较低,如果模型在 4 分钟音频的所有 48 个 bin 中的置信度为 0.10 或更低,我们将该值减半。换句话说,如果所有 48 个部分中都没有鸟鸣(0.10 或更低),我们将概率减半,如果任何 48 个部分中至少有一次鸟鸣,则保持不变。
- 与邻居取最大值 (Max With Neighbors)
- 选择包括前两行和后两行在内的最大值。对于 30 秒的测试样本,如果标签的推理值为 [0.1, 0.3, 0.5, 0.2, 0.4, 0.1],则修改为 [0.5, 0.5, 0.5, 0.5, 0.4]。我们在不同的数据集上进行了许多测试,发现有 25% 的概率分数会下降,因此未包含在最终提交中。
无效尝试 (What didn't work)
- 使用未标记数据进行伪标签 (Pseudo labeling)。
- 训练数据的数据清洗和手动标注。
- 使用新颖的损失函数。BCE 和 Focal Loss 表现几乎最好。
- Manifold Mixup, D-Mixup
- PCEN
- CWT, CQT, VQT
- 可训练前端:Leaf, trainable filterbank, trainable stft, Conv1D
- 重参数化模型 (Reparameterized model)
- Mobilenet V4
- BirdNET embeddings