感谢 Kaggle 和主办方!
非常有趣的比赛!我喜欢能够发挥创造性、探索和发现的机会!在过去的3个月里,我热情地进行了超过1000次实验!
我还喜欢那些只用一个模型就能获得金牌的比赛(而不是大型集成模型)。
感谢所有 Kaggle 参与者分享的精彩讨论和笔记本!
了解测试数据——比赛任务是什么?
本次比赛的任务是预测标注者的意见。通过阅读主办方的论文这里,我们了解到训练数据中有119位总体标注者,测试数据中有20位专家标注者。该论文显示,119位标注者对癫痫(Seizure)的平均预测为18.8%,而20位专家则不太倾向于将其划分为癫痫,平均仅为1.5%。
这是一个很大的差异,因此我们需要使用专家的意见而不是整体意见来训练模型。我们可以通过过滤expert annotators = train.loc[train.vote_count>=10]在训练数据中找到专家标注者。
标注者看到哪些特征?
从论文中我们看到,标注者看到的是2D频谱图和2D波形图。因此,我们将2D频谱图和2D波形图输入到我们的模型中(同时输入1D原始波形也有所帮助)。
使用 Vote>=10 训练3个独立模型
首先,我们使用训练数据(vote_count >= 10,即专家标注者的意见)训练3个独立的模型。
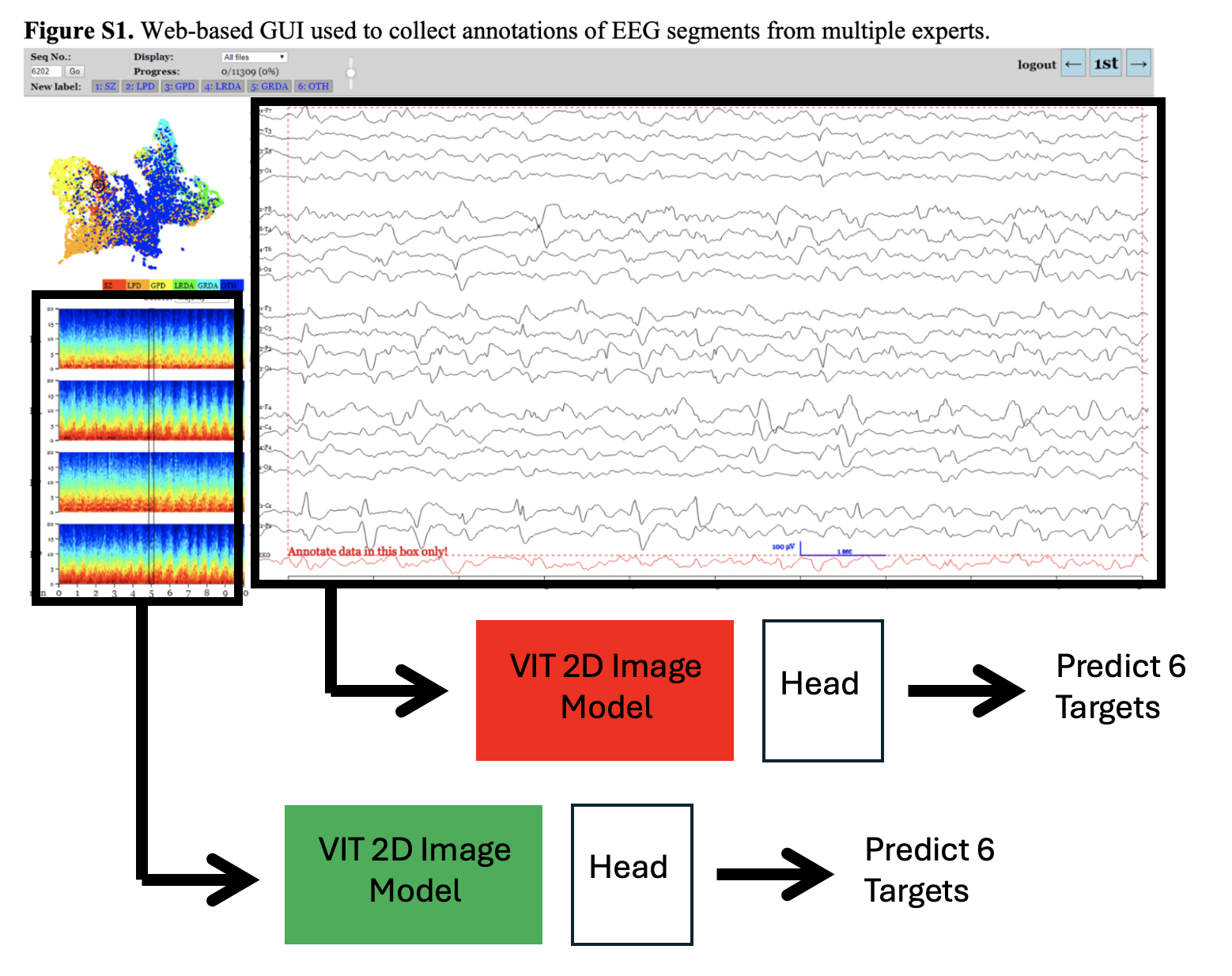
- 模型一:输入从EEG生成的2D频谱图,使用
tiny_vit_21m_512进行6类分类。 - 模型二:输入通过matplotlib绘制的montage波形图并转换为2D图像,使用
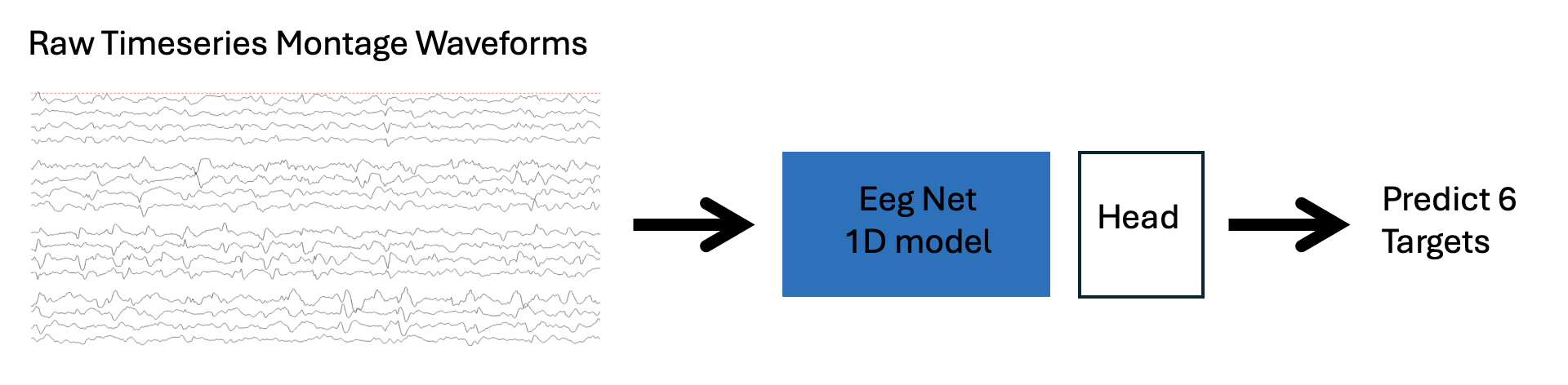
tiny_vit_21m_224进行6类分类。 - 模型三:输入1D原始时序波形,使用
EegNet-1D(链接)进行6类分类。
对 Vote<10 进行伪标签
使用上面的3个单一模型,对训练数据中vote<10的样本进行伪标签。我们将新标签设置为
new_label = 0.1 * old_label + 0.3 * model1 + 0.3 * model2 + 0.3 * model3。
构建 Mega 模型并使用 Vote>=10 加上伪标签的 Vote<10 进行训练
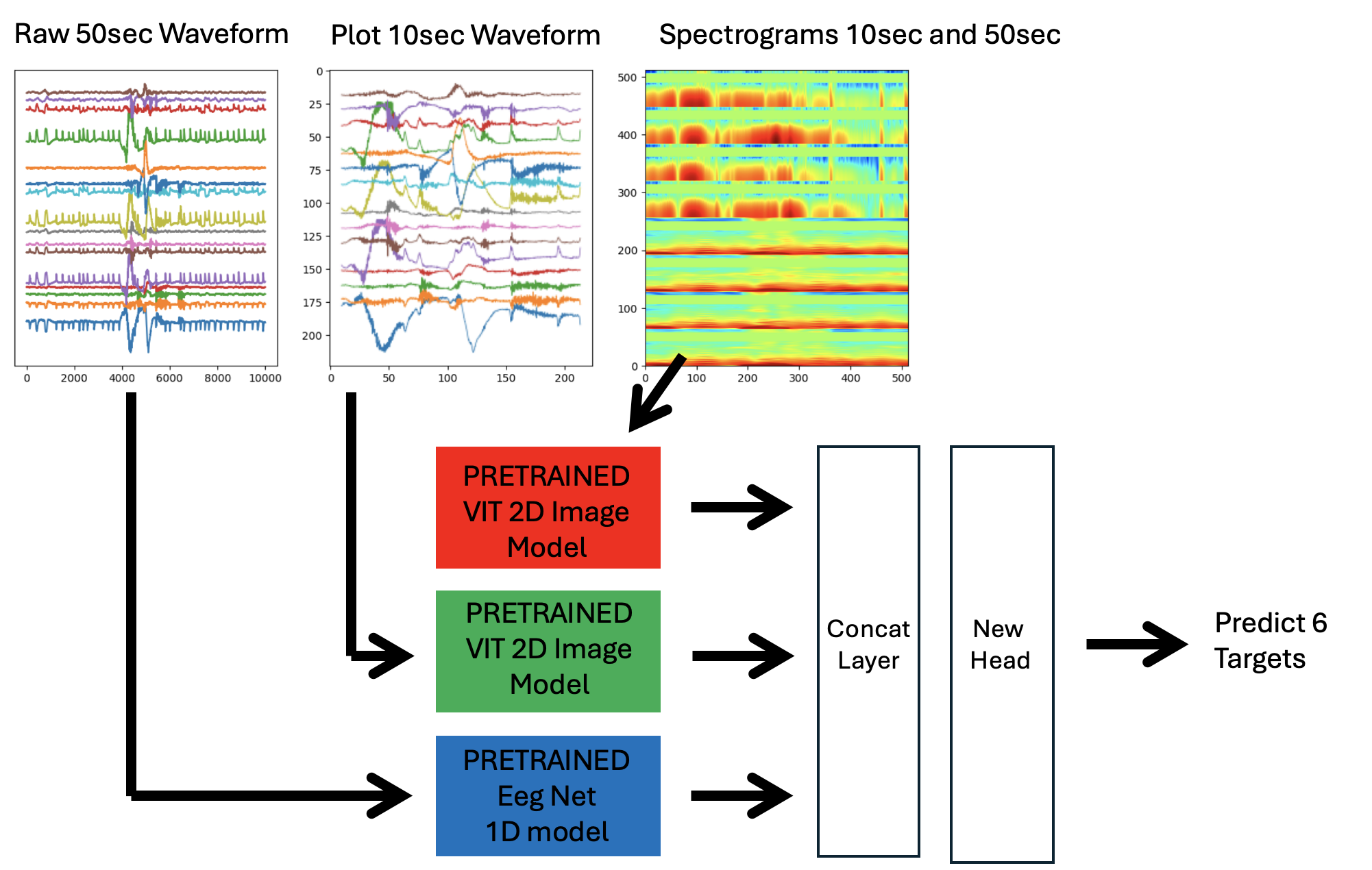
我们加载上述3个预训练模型并去除它们的3个头部。将它们合并为一个模型,拼接它们的最终嵌入并添加一个新的头部。然后我们使用2份vote>=10数据与1份vote<10(伪标签)数据进行训练。(注意,上面的2D频谱图模型实际上在同一张图像中训练了10秒频谱图和50秒频谱图,如下图所示):
单一模型表现
🎉 CV = 0.246,公开 LB = 0.243,私有 LB = 0.290 🎉
更多细节
-
使用 MNE 库对所有原始波形进行预处理:
from mne.filter import filter_data, notch_filter sample = data.T[[0,4,5,6, 11,15,16,17, 0,1,2,3, 11,12,13,14]]\ - data.T[[4,5,6,7, 15,16,17,18, 1,2,3,7, 12,13,14,18]] sample = notch_filter(sample.astype('float64'), 200, 60, n_jobs=32, verbose='ERROR') sample = filter_data(sample.astype('float64'), 200, 0.5, 40, n_jobs=32, verbose='ERROR') sample = np.clip(sample,-500,500) sample = np.nan_to_num(sample, nan=0) - 使用全部 107k 行训练数据(而不是每个 eeg_id 只取一行)。
-
在数据加载器中使用
torchaudio.transforms.MelSpectrogram读取所有 EEG parquet 文件到 CPU RAM 并生成频谱图,使用eeg_label_offset_seconds进行裁剪:import torchaudio.transforms as T # 50秒频谱 make_spec1 = T.MelSpectrogram(n_fft=2048, win_length=1280, hop_length=19, f_min=0, f_max=20, sample_rate=200, n_mels=64).to(device) # 中间10秒频谱 make_spec2 = T.MelSpectrogram(n_fft=1280, win_length=32, hop_length=4, f_min=0, f_max=20, sample_rate=200, n_mels=64).to(device) - 每个 epoch 对每个唯一的
eeg_id只训练一个样本,但从该 eeg_id 的所有样本中随机挑选1个:train = train.loc[train.eeg_id == EEG_ID].sample(1)。 - 在生成频谱图之前,在数据加载器内对原始波形进行数据增强(而非对频谱图)。
- 使用数据增强方法:“大脑左右翻转”、“大脑颞叶-矢状面翻转”、“波形裁剪-缩放”、“波形反转”、“频率丢弃”。
- 对2D频谱图使用
tiny_vit_21m_512,对2D波形图使用tiny_vit_21m_224。 - 对1D原始波形使用 Nischay 的
EegNet-1D(链接)模型。 - 根据我的讨论帖子(链接)分别调优每个模型的学习率和学习计划。
- 使用
vote>=10进行交叉验证,观察到 CV 与 LB 完美相关。
推理代码已发布
我的单一模型推理笔记本已发布这里。该单一模型获得金牌第14名。我的最终提交是将该模型与其他模型集成,获得金牌第8名。
该代码详细描述了 PyTorch 模型细节、预处理细节、PyTorch 数据加载器细节以及数据增强细节。祝您使用愉快!