第10名解决方案
这是一场有趣的比赛,我要感谢我的队友 @samfc10 以及所有参与组织比赛的工作人员。
这是一个简单的教科书式解决方案,严重依赖外部TMA数据和强标签。整个流程中没有什么特别或新颖的内容。
相关资源
推理代码 https://www.kaggle.com/code/gunesevitan/ubc-ocean-inference libvips/pyvips安装与入门 https://www.kaggle.com/code/gunesevitan/libvips-pyvips-installation-and-getting-started UBC-OCEAN - JPEG数据集管道 https://www.kaggle.com/code/gunesevitan/ubc-ocean-jpeg-dataset-pipeline UBC-OCEAN - 探索性数据分析 https://www.kaggle.com/code/gunesevitan/ubc-ocean-eda UBC-OCEAN - 数据集 https://www.kaggle.com/datasets/gunesevitan/ubc-ocean-dataset GitHub代码仓库 https://github.com/gunesevitan/ubc-ovarian-cancer-subtype-classification-and-outlier-detection1. 原始数据集
WSI(全切片图像)
WSI的掩码被缩放到缩略图尺寸。从缩略图中提取WSI和掩码的图块,步长为384,并填充至512。在这些填充后的图块和掩码上训练MaxViT Tiny FPN模型。分割模型的输出通过sigmoid激活,并在激活后应用3倍TTA(水平、垂直和对角线翻转)。
由于模型在图块上训练并后期合并,最终的分割掩码预测呈现块状。
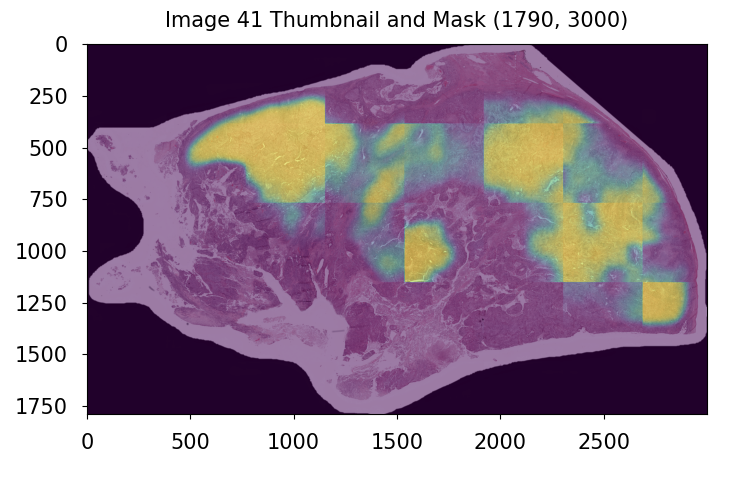
分割掩码预测被转换为8位整数,并使用最近邻插值法上采样至原始WSI尺寸。
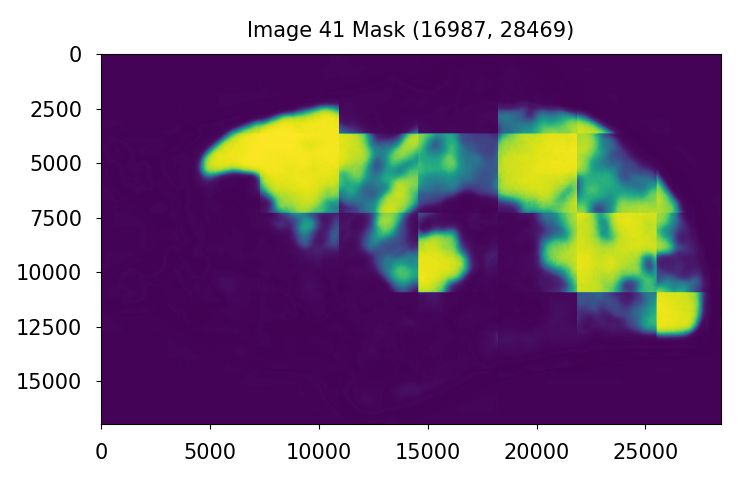
- WSI及其掩码预测以1024步长进行最大次数裁剪
- 根据掩码面积按降序对裁剪区域进行排序
- 取前16个裁剪区域并赋予WSI标签
TMA(组织微阵列)
使用下方函数在TMA上删除标准差较低的行和列。此预处理的目的是去除白色区域,使WSI和TMA尽可能相似。使用更高的阈值会删除组织区域的图像,因此标准差阈值设为10。
def drop_low_std(image, threshold):
"""
删除低于给定标准差阈值的行和列
参数
----------
image: numpy.ndarray, 形状为 (高度, 宽度, 3)
图像数组
threshold: int
标准差阈值
返回
-------
image: numpy.ndarray, 形状为 (裁剪后高度, 裁剪后宽度, 3)
裁剪后的图像数组
"""
vertical_stds = image.std(axis=(1, 2))
horizontal_stds = image.std(axis=(0, 2))
cropped_image = image[vertical_stds > threshold, :, :]
cropped_image = cropped_image[:, horizontal_stds > threshold, :]
return cropped_image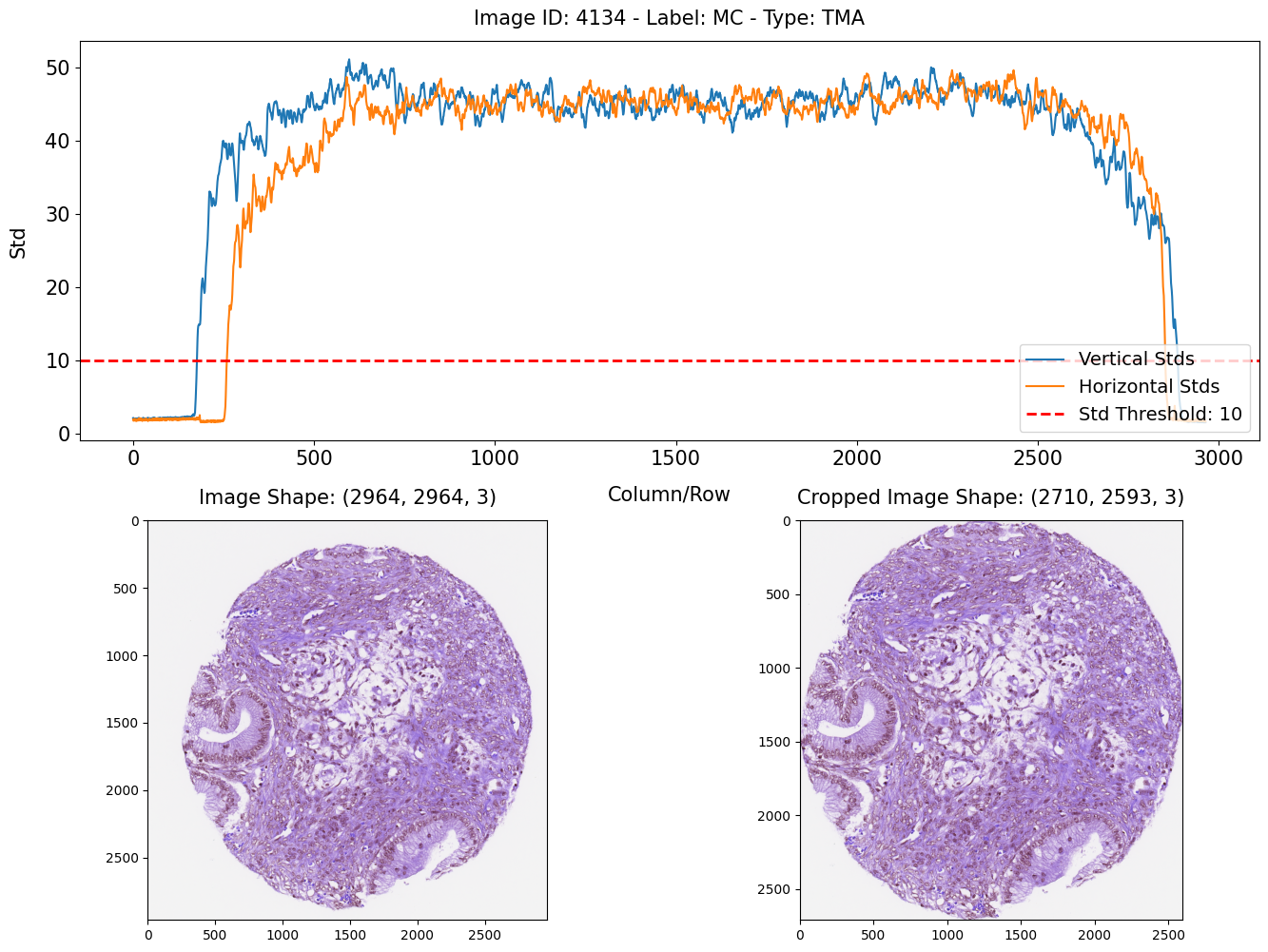
2. 验证
采用多标签分层k折作为交叉验证方案。数据集被分为5折,使用label和is_tma列进行分层。
3. 模型
使用EfficientNetV2 small模型作为骨干网络,配合常规分类头。
4. 训练
使用带类别权重的CrossEntropyLoss作为损失函数,类别权重计算为n / 第i类数量。
使用AdamW优化器,学习率为0.0001,配合余弦退火调度器,最低学习率为0.00001。
使用AMP实现更快训练和正则化效果。
每折训练15个epoch,选择平衡准确率最高的epoch。
训练时使用的数据增强包括:
- 将TMA缩放至1024尺寸(WSI裁剪图块已是1024)
- 放大归一化(随机将WSI缩放至512再恢复至1024)
- 水平翻转
- 垂直翻转
- 随机90度旋转
- 带45度旋转和轻微平移/缩放的Shift scale rotate
- 强色调和饱和度的颜色抖动
- 通道重排
- 高斯模糊
- 粗粒度丢弃(Cutout)
- ImageNet归一化
5. 推理
推理流程使用5折EfficientNetV2 small模型,每折模型预测后取平均值。
应用3倍TTA(水平、垂直和对角线翻转),取预测平均值。
每张WSI提取16个裁剪区域并取预测平均值。
单张图像的平均池化顺序:
- 预测原始图像和翻转图像,softmax激活后取平均
- 使用所有折模型预测并取平均
- 如果是WSI,预测所有裁剪区域并取平均
6. 方向转变
当时模型OOF分数为86.70(TMA: 84, WSI: 86.59),但LB分数仅为0.47(私下0.52/32-42名),非常低。
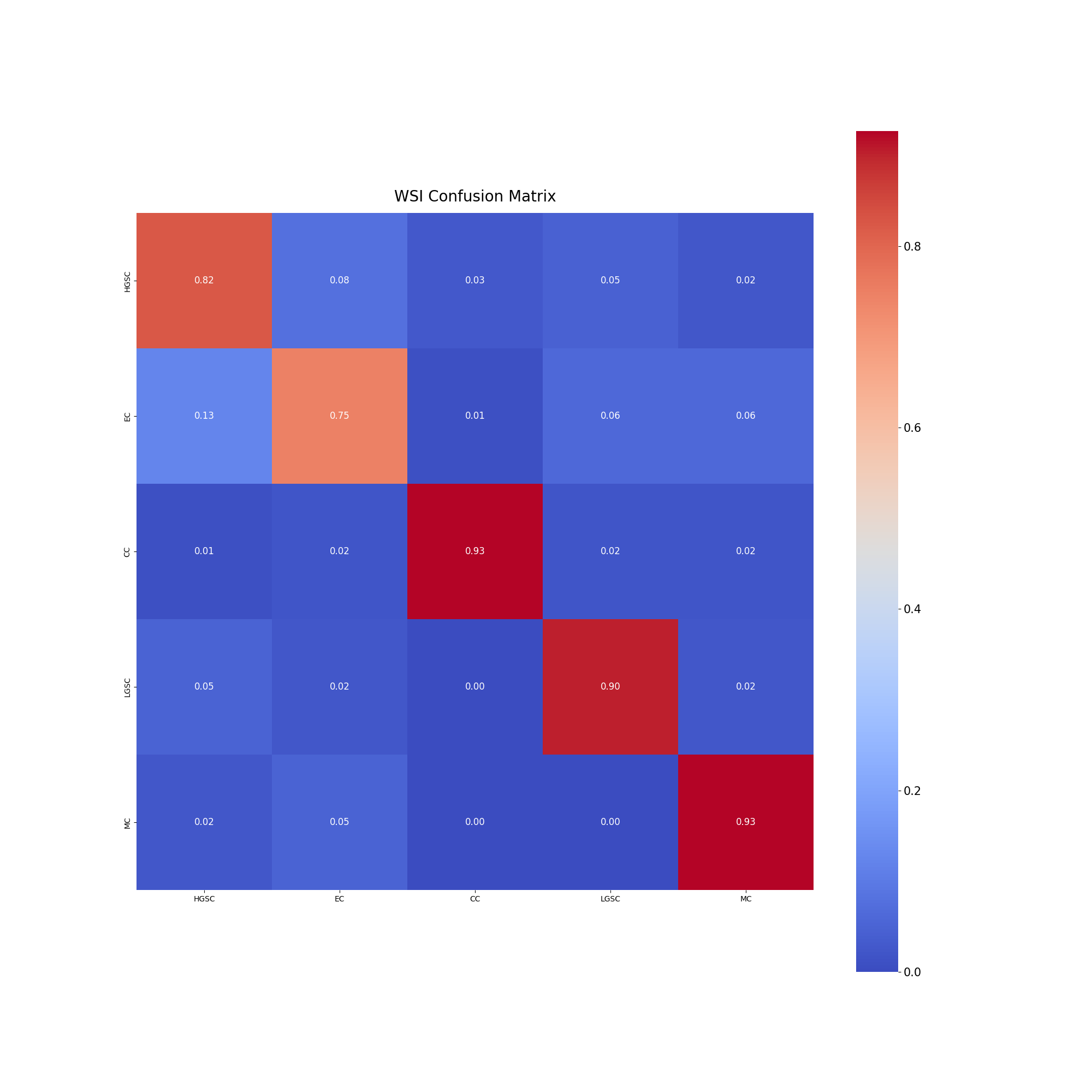
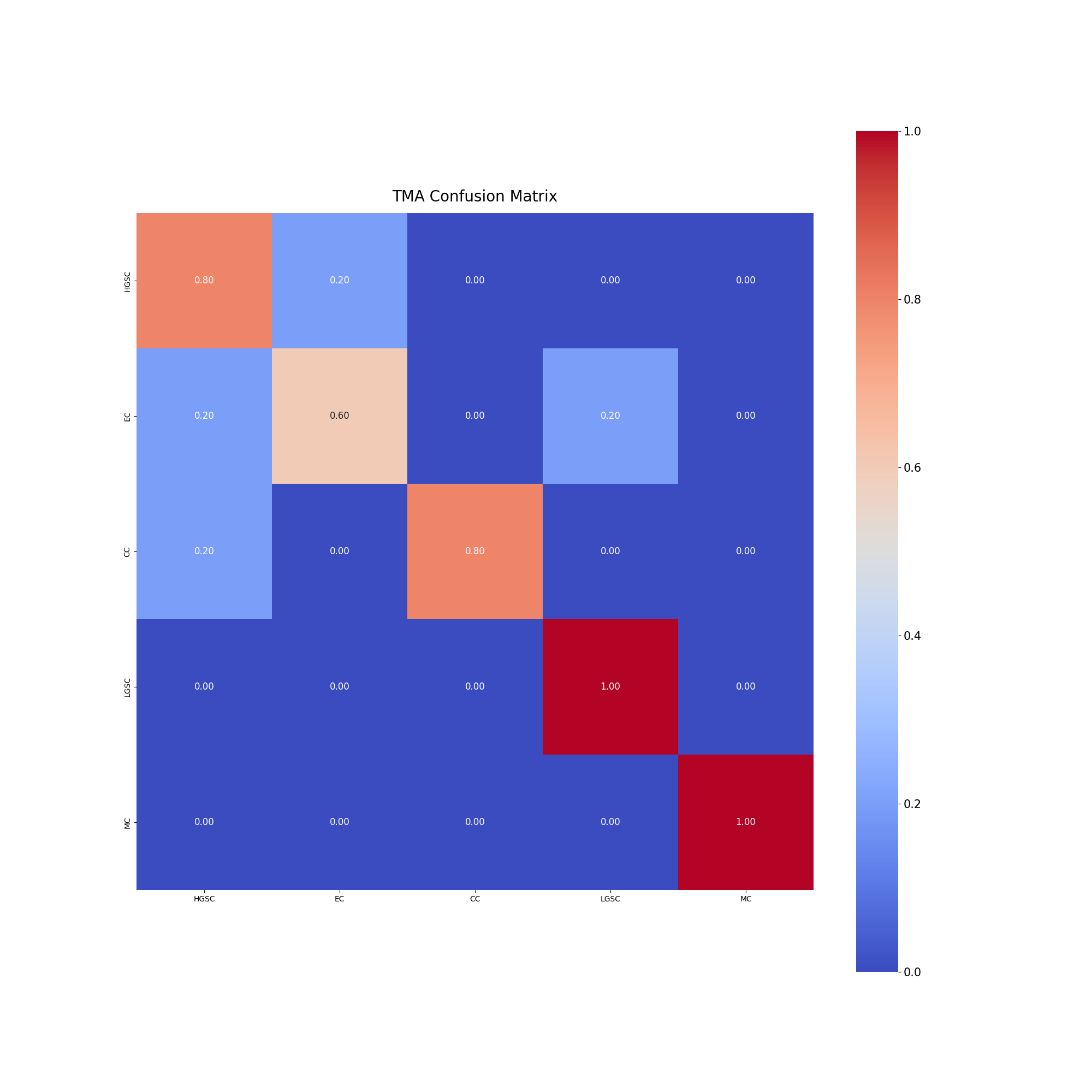
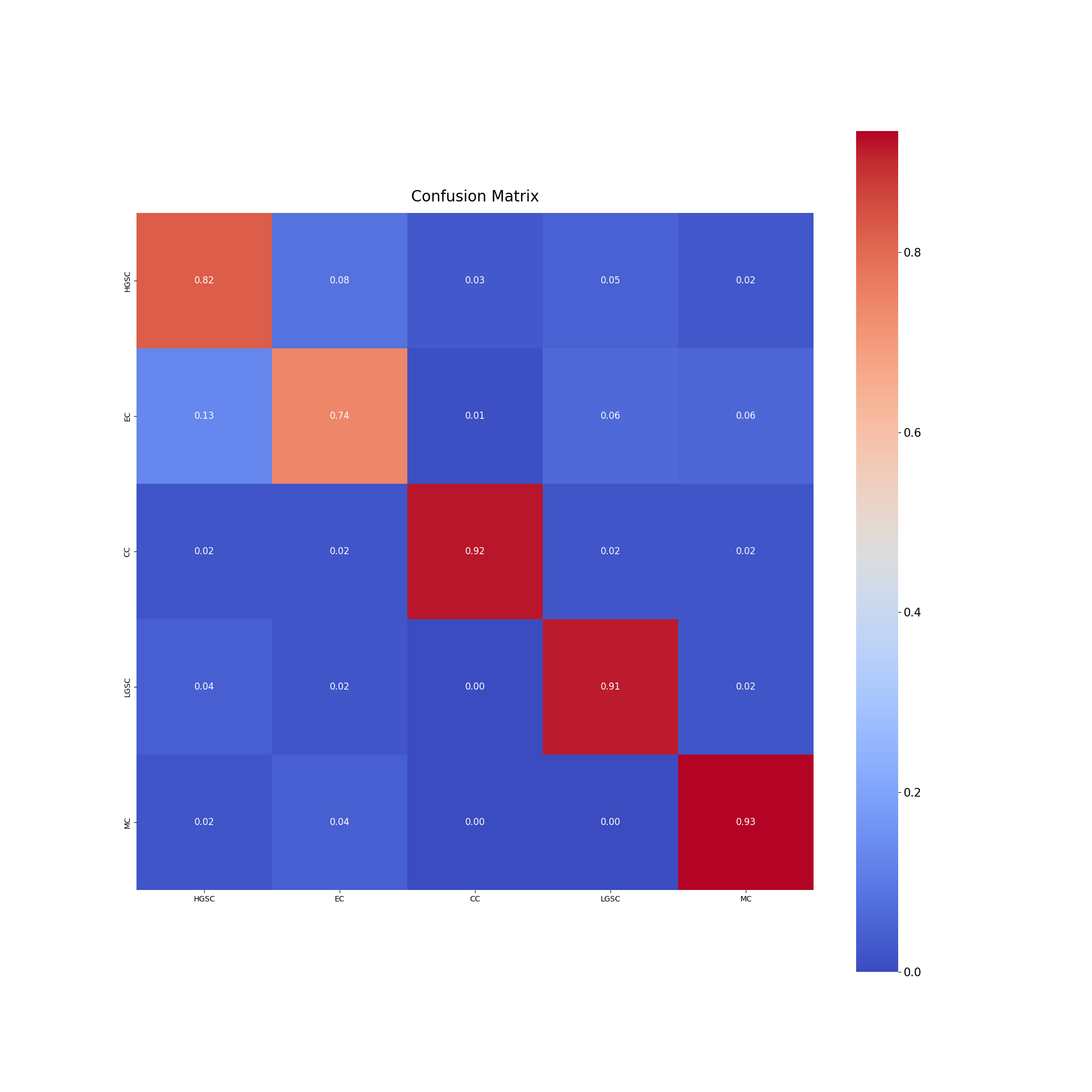
我注意到有些人OOF分数较低但LB分数更高,而我卡在0.47一段时间了。我曾花两周时间参加Optiver竞赛然后回归。我决定投入时间寻找外部数据,因为完全推翻现有流程重新开始并不明智。
7. 外部数据
UBC Ocean
最明显的是测试集中被模型 confidently 分类为HGSC的图像。从该图像提取16个裁剪区域并赋予HGSC标签。
斯坦福组织微阵列数据库
从此处下载134个卵巢癌TMA。
使用以下类别映射:
CLASS_MAPPING = {
'fibroma of ovary spindle cell fibroma of ovary': 'Other',
'carcinoma papillary serous': 'HGSC',
'carcinoma endometrioid': 'EC',
'lymphoma precursor B lymphoblastic': 'Other',
'carcinoma adeno': 'HGSC',
'carcinoma clear cell': 'CC',
'carcinoma mucinous': 'MC',
'carcinoma adeno mucinous': 'MC',
'seminoma dysgerminoma': 'Other'
}kztymsrjx9
从此处下载此数据集。将Serous目录中的图像赋予HGSC标签,未使用Non_Cancerous目录。共找到398个卵巢癌TMA。
tissuearray.com
从此处截取高分辨率预览图。共找到1221个卵巢癌TMA。
usbiolab.com
从此处截取高分辨率预览图。共找到440个卵巢癌TMA。
proteinatlas.org
从此处下载图像。共找到376个卵巢癌TMA。
数据汇总
以下是找到外部数据的来源:
| 来源 | 图像数 | 类型 | HGSC | EC | CC | LGSC | MC | Other |
|---|---|---|---|---|---|---|---|---|
| UBC Ocean公开测试集 | 16 | WSI | 16 | 0 | 0 | 0 | 0 | 0 |
| 斯坦福组织微阵列数据库 | 134 | TMA | 37 | 11 | 4 | 0 | 4 | 78 |
| kztymsrjx9 | 398 | TMA | 100 | 98 | 100 | 0 | 100 | 0 |
| tissuearray.com | 1221 | TMA | 348 | 39 | 24 | 140 | 100 | 570 |
| usbiolab.com | 440 | TMA | 124 | 40 | 29 | 89 | 68 | 90 |
| proteinatlas.org | 376 | TMA | 25 | 155 | 0 | 63 | 133 | 0 |
8. 最终迭代
最终数据集(包含每个WSI的16个裁剪区域)的标签分布如下:
- HGSC: 4127
- EC: 2252
- CC: 1666
- MC: 1066
- LGSC: 969
- Other: 738
图像类型分布如下:
- WSI(16x 1024裁剪): 8224
- TMA: 2594
所有外部数据都拼接到每折的训练集中。验证集未改变以保持结果可比性。OOF分数从86.70降至83.85,但LB分数跃升至0.54。我认为这一提升与Other类有关,但改进不够明显。此时我推测私有测试集可能包含更多Other类样本,这在Kaggle竞赛中很常见。本次竞赛的关键在于预测TMA和Other类,因此私有测试集很可能包含更多此类样本。我决定信任LB分数,选择LB分数最高的提交。该提交在公开榜得分为0.54,在私有榜得分为0.58。