第33名解决方案:GST图分段训练方法详解与讨论
首先,感谢Kaggle和比赛主办方举办这场激动人心的比赛,并祝贺所有获奖者。我想从图分段训练(GST)的角度分享我的解决方案(虽然并不那么出色)。代码已发布在此处。
概览
- 数据清洗与预处理
- 按照此处说明添加新特征
- 删除恒定和准恒定特征
- 对
shape_element_type_is_X相关特征进行标签编码 - 对最大值大于20的特征进行对数变换
- 模型架构
- 以早期连接方式训练所有模型(即在获取完整图上下文前融合节点和配置特征)
- 使用
SAGEConv作为GNN模块
- 训练策略
- 使用GST(带历史嵌入表和过时嵌入dropout)以集合特定的方式训练layout模型(即每个集合一个模型)
- 每轮迭代采样配置子集来训练模型
- 实验设置
- 损失准则:layout使用
PairWiseHingeLoss,tile使用ListMLE - 优化器:
AdamW,基础学习率1e-3(我在增加训练轮数时降低学习率) - 学习率调度器:余弦调度(无预热)
- 检查点:始终选择最后一轮的模型
- 损失准则:layout使用
数据清洗与预处理
我通过简单的四阶段工作流处理数据。首先,我发现某些特征在所有数据集中都是恒定的,这些可视为冗余维度并直接删除。此外,恒定比例超过0.999的特征(即准恒定特征)也被移除。然后,我对剩余的shape_element_type_is_X相关维度进行标签编码,这些可以用稠密嵌入表示。最后,考虑到特征值范围广泛(且存在一些异常值),我简单地使用np.log1p对最大值大于20的特征进行对数变换。
处理后,xla和nlp的节点特征维度分别降至116和50(不添加新特征时为89和33)。
交叉验证方案
考虑到xla和nlp在公开榜上分别只有约4个和8个图被评估,我尝试通过在运行时上进行分层拆分来扩大验证集,这可以在一定程度上平衡图本身的特性(我在此notebook中探索了图统计量与运行时之间的关系)。不过,我认为这与直接使用官方训练-验证拆分差别不大。
模型架构
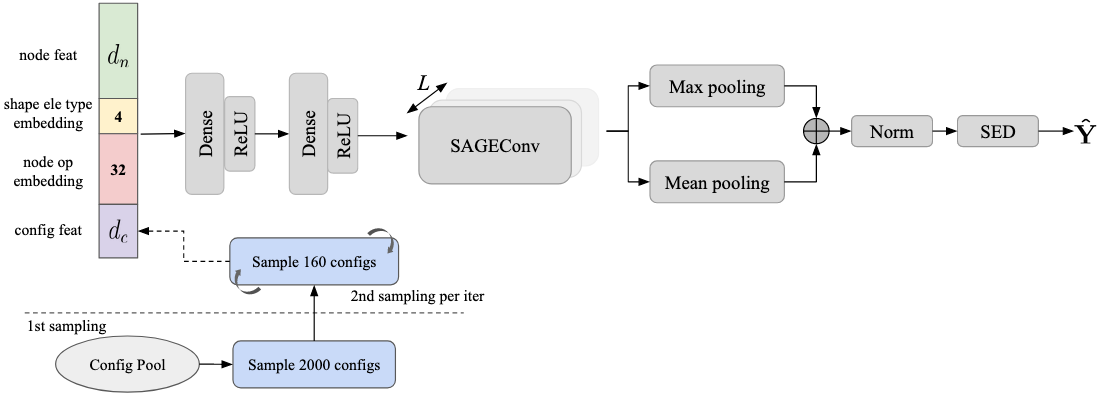
上图展示了模型架构的概览,其中\\(d_n \\)和\\(d_c \\)分别表示节点和配置特征的维度,\\(L \\)是图卷积层的数量。
自10月22日首次提交以来,我一直使用早期连接来融合节点和配置特征。在试验了不同的GNN模块(如GATConv、GATv2Conv、GINConv)后,SAGEConv始终表现更优,因此我始终坚持使用它。同时\\(L \\)始终设置为3。老实说,我的模型架构中没有什么花哨的设计,因此我想更多地讨论训练策略。
训练策略 - 图分段训练(GST)
考虑到内存限制,我很快决定选择现成的GST作为我的训练框架。由于GST的官方实现存在一些未解决的问题,我重写了不使用GraphGPS的流水线。
GST的主要问题是训练损失随着训练过程推进而增加,但验证性能仍在持续改善。在固定了每个图分段的权重\\(\\eta \\)用于最终求和池化后,训练损失如所示正常下降(特别感谢@dsfhe49854的分析):

让我们看看原文中如何推导\\(\\eta \\)。设\\(n \\)为一个图的分段数量,\\(k \\)为每轮迭代训练的分段数量,另设\\(p \\)为过时嵌入dropout的dropout比率。假设每轮迭代仅采样一个分段进行训练(即\\(k = 1\\)),如论文所述。已训练分段的权重\\(\\alpha \\)可推导如下:
$$
(n-k)p + k\\alpha = n
$$
$$
\\alpha = (1-p)\\frac{n}{k} + p
$$
背后的逻辑是,最终运行时估计是所有分段运行时的求和池化。考虑到某些分段以概率\\(p \\)被丢弃,我们需要增加已训练分段的权重来进行补偿。然而,问题是历史嵌入表中的大多数条目都是零。因此在早期轮次中,目标可以近似为:
$$
\\hat{y} = \\alpha \\hat{y}_{i} ,
$$
其中\\(\\hat{y} \\)是当前图的预测运行时,\\(\\hat{y}_{i} \\)是当前图第\\(i \\)个分段的预测运行时。有趣的是,我观察到与固定\\(\\eta \\)相比,非固定\\(\\eta \\)始终带来更好的泛化能力。此外,如果模型训练足够多的迭代次数,训练损失实际上会下降(红线在大约100轮时转向)。
实验结果
下表展示了我的最终提交的本地CV分数。
| 集合 | CV |
|---|---|
| tile | 0.9551 |
| xla-default | 0.3188 |
| xla-random | 0.5569 |
| nlp-default | 0.5053 |
| nlp-random | 0.8845 |
对我无效的方法
- 使用其他GNN模块(如
GATConv、GATv2Conv、GINConv) - 在整个数据集上重新训练模型
- 使用random的预训练权重微调default
- 冻结网络的不同部分没有区别
- 使用其他策略对图进行分段(如Metis)
总结
在所有实现中只坚持一种方法(GST)并不好,我应该探索其他潜在的解决方案,就像我迄今为止消化的所有精彩分享一样。虽然这次的结果并不那么理想,但我会继续进步并向顶尖选手学习。这段旅程永不停歇!感谢您的耐心!