分段排序(LB 第15名)
感谢 Kaggle 举办这场比赛,也感谢社区的分享。这是我第一次参加 NLP 比赛,所以我的解决方案中没有太多 NLP 相关的分享,主要是任务相关的技巧。
太长不看 (TL;DR)
一个 deberta-v3-small 模型就足够了,核心是排序方法,利用子序列(分段)。
我的解决方案只使用了排序方法。给定一个 markdown 单元格和一组排序好的 code 单元格,预测该 markdown 单元格的位置。这里的主要区别在于,我不使用整个 notebook 来对一个 markdown 单元格进行排序,而只是使用它的一部分,这部分可以被称为一个分段。
例如,给定一个包含 40 个 code 单元格的 notebook,我们可以将其分为 4 个子分段,每个分段包含 10 个 code 单元格。然后,我们在整个 notebook 的 10 个 code 单元格中对每个 markdown 进行排序。
关于这个方法有一个有趣的思考:如果我们把这 40 个 code 单元格分成 40 个分段,每个分段只包含 1 个 code 单元格,那么这个方法就等同于成对排序;如果不分割 notebook(或者将其分成 1 个分段),那么它就等同于全排序。
分段排序
全排序方法(也在此处开源)是预测 markdown 单元格在整个 code 单元格中的位置。输入模型的序列通常是这样的:markdown_cell + code_cell + code_cell ... code_cell,但是许多序列对于 Transformer 模型来说太长了(即使是 Longformer),处理长序列问题的一种简单方法是截断 markdown_cell 和 code_cell 的长度,以使组合后的序列长度可以接受。但是截断得越多,我们丢失的信息就越多,那么我们如何才能尽可能保留信息,同时获得合理的输出序列长度呢?
为了解决全局信息和序列长度的平衡问题,我想出了分段排序的方法。
一个分段是 notebook 排序后 code 单元格的一部分。如果用 M 表示 notebook 中 code 单元格的数量,用 N 表示一个分段中 code 单元格的数量,那么一个 notebook 可以被分成 C 个分段,其中 C 等于 math.ceil(M / N)。
既然我们有了 notebook 的多个分段,而该 notebook 中的 markdown 单元格只能属于其中一个分段,我们必须首先确定一个 markdown 是否属于某个分段,然后在该分段内进行排序。所以模型有两个头,一个用于分类,一个用于排序。下图展示了详细信息。
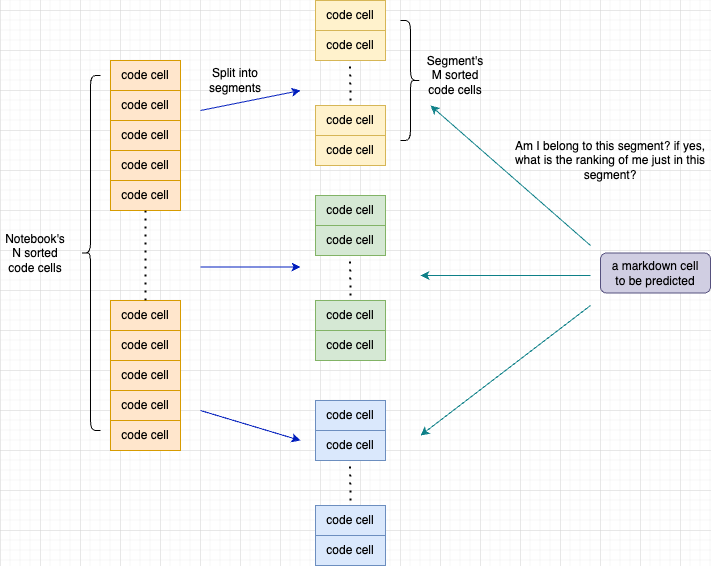
分段中的单元格数量(N)在这里是一个非常重要的超参数。较大的 N 会加快训练和推理速度,较小的 N 可以带来更多的上下文信息。我最终选择了 N = 16,序列最大长度 = 384。
其他重要的任务相关技巧
结合语言模型训练
实际上我的模型还有第三个头,用于语言建模。该头的输入是 <previous_cell_encode + <anchor_cell_encode + <next_cell_encode,正样本意味着这三个单元格是连续的,负样本意味着不连续,它们只是从 notebook 中随机选取的(但不是前一个和后一个单元格)。
填充是一种浪费
我尝试尽可能保留信息并减少 <pad> 标记。给定以下 5 个单元格,我们如何截断以保持 200 的长度?我没有以固定长度截断每个单元格,而是使用了下图所示的方法。或者看看这个测试用例。

感谢阅读。