第41名方案
首先,感谢 Kaggle 和竞赛主办方举办了这场充满挑战的比赛 —— Google AI4Code:理解 Python Notebook 中的代码,预测代码与注释之间的关系。这篇文章总结了我们团队的努力,能与队友合作是一次很棒的经历!这是我们团队集体努力的成果总结。
概述
基于 Khôi 的初步想法,我们做了一些修改以获取更多的全局上下文信息。我们采样了 45 个单元格,并使用较短的代码单元格长度(10 个 token)。如果 notebook 中的单元格少于 45 个,我们会根据代码单元格的数量动态调整代码单元格的最大长度。
集成来自两种训练设置的模型(我们的设置和 Khoi Nguyen 的设置 —— 20 个代码单元格,每个 23 个 token)也提升了 CV 和 LB 的分数(具体数字我们记不清了)。
- 模型:一些 Point-wise 模型的加权平均,例如:Distilbert-base-uncased, Deberta-v3-base 和 Codebert-base。
- 数据:所有竞赛训练数据,无外部数据。交叉验证分割比例:90/10。
- 硬件:两块 A6000-48GB。最大的模型训练了 3-4 天,轻量级模型如 distilbert 训练了 1-2 天。
本地 CV 的一些结果详情见下图:
初始实验
初始实验没有打败 Khoi 的基线:
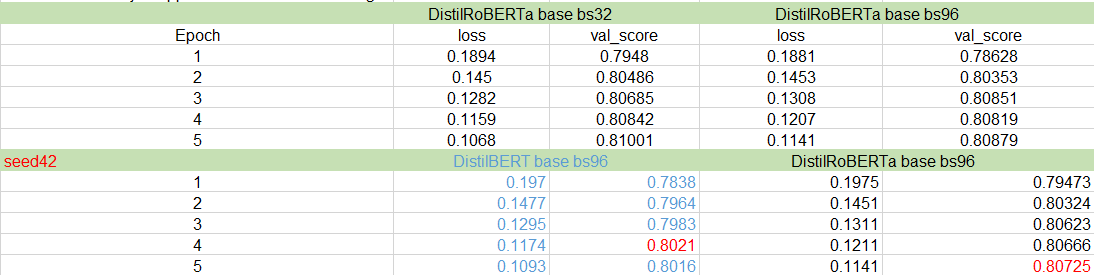
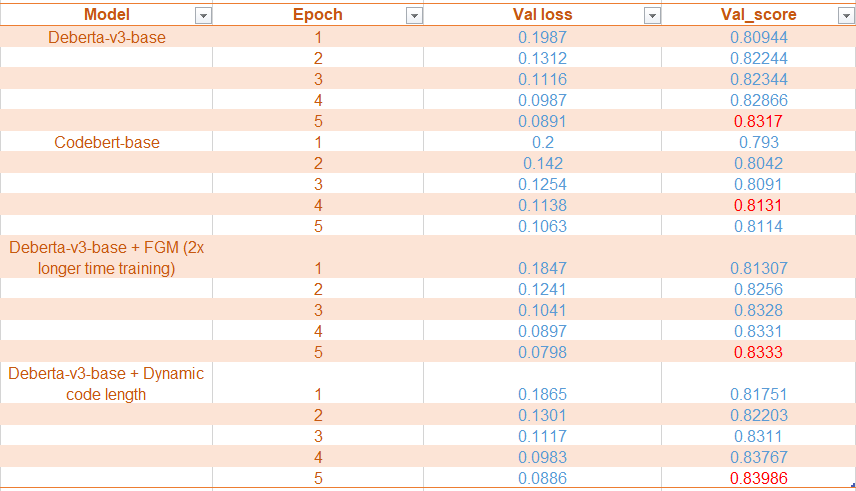
基于代码单元格数量的动态 tokenizer 和 FGM 训练帮助提升了本地 CV 和 LB 的分数:
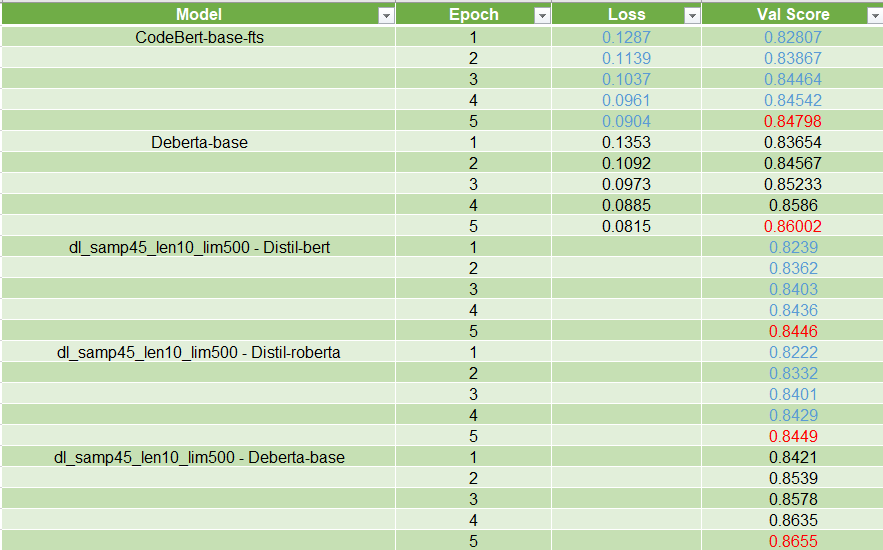
最终 & 最佳实验
在本地 CV 和 LB 上表现最好的模型是 Deberta-v3-base。
推理代码: Inference Ensemble Final Submission
有效的方法
[高影响力] 想法
- 基于代码单元格数量的动态 tokenizer:本地 CV +0.007,LB +0.005。
- 本地 tokenizer 以提升训练速度。
[中等影响力] 想法
- MLM 预训练(15% 概率随机 mask token),在除 1000 个验证样本外的所有数据上进行:本地和 LB +0.002(提升不大,且预训练耗时较长)。
- FGM 训练:提升本地和 CV +0.002,但训练时间翻倍。
无效的方法
- 更大的模型:Deberta-v3-large, Deberta-v3-xlarge。
- AWP/Fast AWP 训练:未提升本地 CV 和 LB 分数。
- EMA 训练。
- 自定义头部:
- mean/max pooling
- concat mean-max pooling
- concat last 4 layers
- Attention pooling
- LSTM/ Bi-LSTM
补充背景(没时间尝试的想法):
我们真的很想测试以下论文中的想法,但我们确实没有足够的时间和计算资源。
- Deep Attentive Ranking Networks for Learning to Order Sentences - 论文链接
- Efficient Relational Sentence Ordering Network - 论文链接
- Neural Sentence Ordering Based on Constraint Graphs - 论文链接
- Is Everything in Order? A Simple Way to Order Sentences - 论文链接
- Sentence Ordering and Coherence Modeling using Recurrent Neural Networks - 论文链接
- 知识蒸馏
- 增强技术:Mixup, Random mask