第9名方案:DeBERTa 为王,纯 BERT 模型集成
我的方案是一个简单的 BERT 模型集成。
我曾尝试使用不同模型的召回率通过 LGB 进行 L2 重排,但没能成功,有点遗憾:(。所以这里没有堆叠,只是通过优化后处理(使用 Optuna 搜索)对一级 BERT 模型进行了简单的集成。
- 最佳单模型是 deberta-v3-large!
deberta-v3-large 在 feedback-prize 和 nbme 比赛中都是王者 😉
deberta-v3-large + maxlen 1536 单模型(在所有 15k 数据上训练)可以达到 LB 705, PB 718
提交运行时间约 34 分钟,我后来提交了该模型的 5 折测试,分数为 LB 708, PB 723
相同模型结构的 Longformer maxlen 1536 只能达到 LB 690, PB 705 - Longformers(maxlen >= 1024) 有所提升,但 shortformers(maxlen == 512) 帮助更大!
仅使用两个分开训练的 512 长度模型,我们就能得到 LB 705, PB 717。
deberta-v1-xlarge 前 512 + deberta-v1-xlarge 后 512
仅用 10 个 shortformers 集成可以得到 LB 712, PB 723。
模型列表与权重
| 序号 | 模型路径 | 模型名称 | 权重 |
|---|---|---|---|
| 0 | ../input/feedback-model0 | base.deberta-v3.start | 1 |
| 1 | ../input/feedback-model1 | base.deberta-v3.end | 1 |
| 2 | ../input/feedback-model2 | base.deberta-v3.se | 1 |
| 3 | ../input/feedback-model3 | large.deberta-v2-xlarge.start | 1 |
| 4 | ../input/feedback-model4 | large.deberta-v2-xlarge.se2 | 1 |
| 5 | ../input/feedback-model5 | base.deberta.start | 1 |
| 6 | ../input/feedback-model6 | base.deberta.mid | 1 |
| 7 | ../input/feedback-model7 | base.electra.start | 1 |
| 8 | ../input/feedback-model8 | large.deberta-v3.start.mui-end-mid | 2 |
| 9 | ../input/feedback-model9 | large.electra.start.mui-end-mid | 2 |
什么提升了单模型性能?
- 请务必不要删除 '\n',这是非常重要的特征。我将 '\n' 更改为新词 '[BR]',以确保所有模型(如 roberta 的 tokenizer)都能正确处理。
- BERT 之上的词级 LSTM 帮助很大!(使用 torch scatter_add,LB +2K, PB +3K)
- 我使用了多目标模型,标记分类(8 类)+ 分隔符分类(二分类)
- Lovasz loss 有一点帮助 (LB 4K,但在 PB 上没有收益)
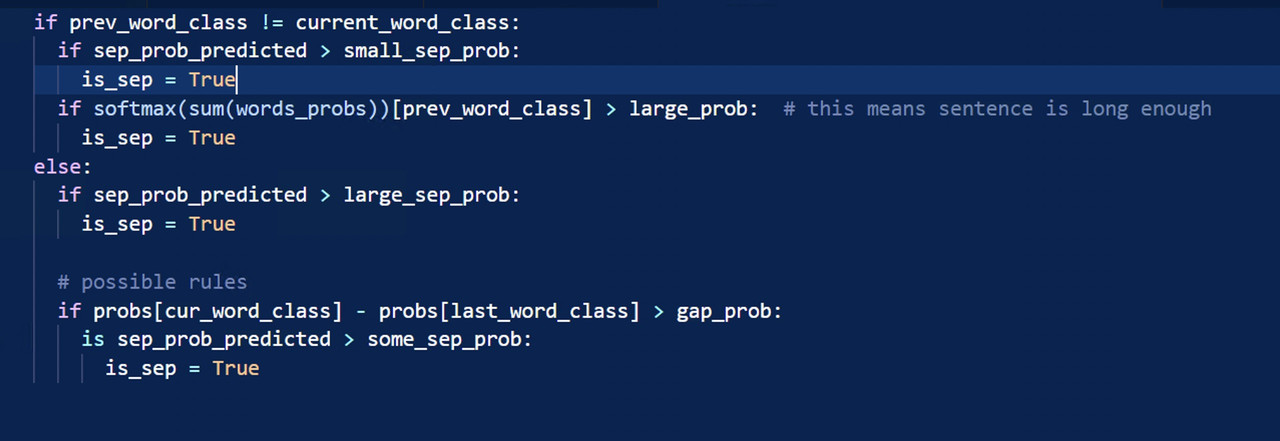
后处理
如何分割很重要,我发现下面的规则很有帮助!但它还是比不过 LGB :)