第55名方案 – Shortformer + 滑动窗口 + 依赖主题的后处理
首先,非常感谢比赛主办方和Kaggle组织了这次比赛。我迫不及待地想详细阅读所有其他的方案分享。
我的方案是不同BERT骨干网络的加权集成以及依赖主题的后处理。为了在本次比赛中训练类似Shortformer的模型,我使用了滑动窗口方法。虽然我只获得了第55名,但我希望能与大家分享并讨论一些新想法。
滑动窗口训练 / 推理
默认情况下,类似Shortformer的模型无法处理长文档。为了克服这个问题,我将长文章分割成带有左右上下文的块。然后我只对块的中间部分进行预测,而不是对上下文窗口进行预测。
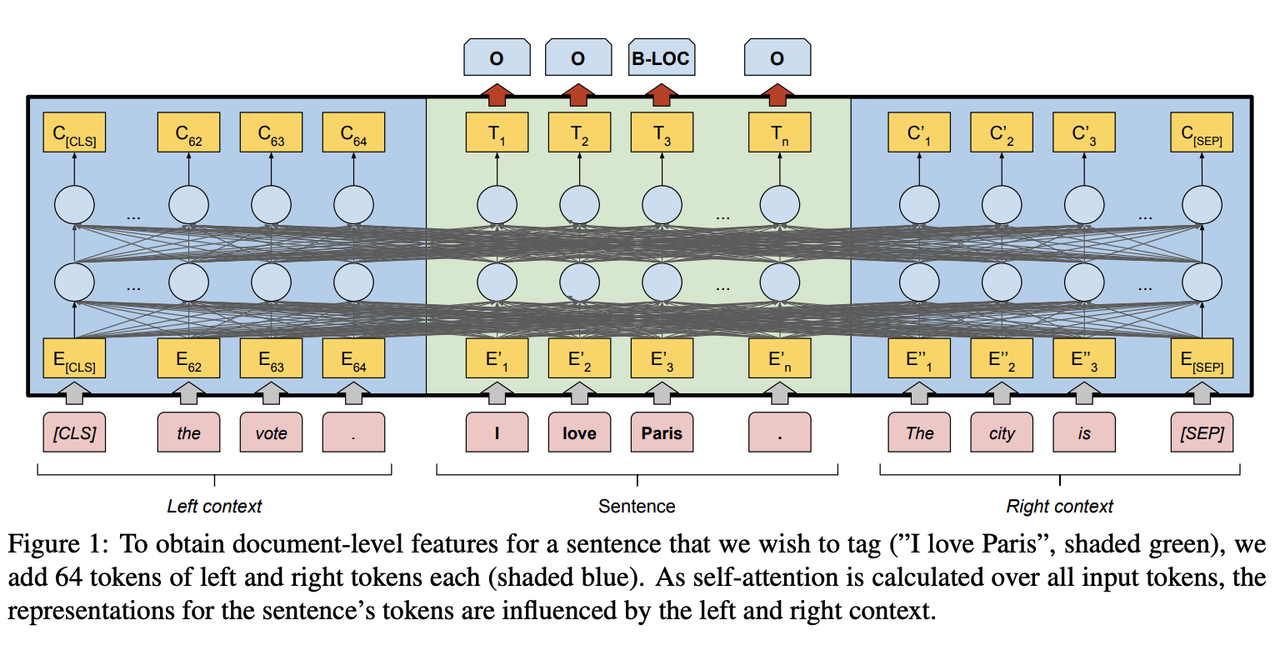
这个方法的灵感来自这篇论文,与应用普通步长相比,它使我的单模型提升了0.005+。
训练设置和超参数
在训练中,我使用的学习率为1e-5,批次大小为4(带梯度累积),线性/余弦学习率计划(预热10%),BIO标签方案和8-bit Adam。
此外,我尝试应用多样本dropout、数据增强、逐渐(解)冻层、(分组)判别式学习率、BIEO标签方案和任务内预训练。然而,所有这些技术都没有带来显著的改进。
误差分析
改进深度学习系统是一个高度迭代的过程。执行误差分析以确定经常改进的领域非常重要。我编写了一个函数,它接收原始的submission.csv、后处理的submission.csv和基本事实train.csv,并排显示它们,同时按从最差到最好/从最好到最差的整体或话语相关性能对其进行排名。这种可视化在整个比赛过程中对我帮助很大。

模型
- DebertaV3-Large
5折,最大长度512,128+128上下文窗口,公开/私有LB 0.698/0.709,CV 0.697 - Funnel-Large
5折,最大长度512,128+128上下文窗口,公开/私有LB 0.692/0.704,CV 0.92 - Roberta-Large
5折,最大长度512,128+128上下文窗口,公开/私有LB 0.684/0.695,CV 0.682 - Longformer-Large
5折,最大长度1536,无上下文窗口,公开/私有LB 0.688/0.699,CV 0.686
集成
我通过应用来自这个讨论的集成伪代码,构建了DebertaV3 (0.4788)、Funnel Transformer (0.3192)、Longformer (0.152)和Roberta (0.05)的加权集成进行提交。
使用加权集成将公开/私有LB提高到了0.702/0.714,而使用平均集成的公开/私有LB为0.700/0.712。
依赖主题的后处理
在比赛初期,我在数据集中发现了15个文章主题。后来Chris在这个讨论帖和Notebook中也揭示了这一点。
使用BERTopic,我快速建立了一个简单的模型,允许我以超过99.5%的准确率预测特定文章的主题。有了这个模型,我可以应用依赖主题的后处理,即为每个主题调整单独的length_threshold和proba_threshold字典,而不是拥有两个全局字典。然而,我认为我的训练/调整设置对于这种后处理来说不是最佳的,因为我在StratifiedKFold中只考虑了话语,而没有考虑主题。如果有正确的CV策略,分数可能还会进一步提高。
即使使用我的CV策略,依赖主题的后处理