第3名解决方案
感谢我的队友 @maxwell110、@niwatori,所有参赛者,以及组织了这场精彩比赛的 Kaggle 管理员。我想简要分享我们的第3名解决方案,这让我获得了我的第5枚金牌。
概述
我们的解决方案基本上是一个类似 AlphaZero 的策略/价值双网络 + MCTS(蒙特卡洛树搜索)。我们通过数月的迭代构建了这个智能体,包括行为克隆的预训练、深度强化学习的模型训练、MCTS 改进、基准评估以及对局生成。
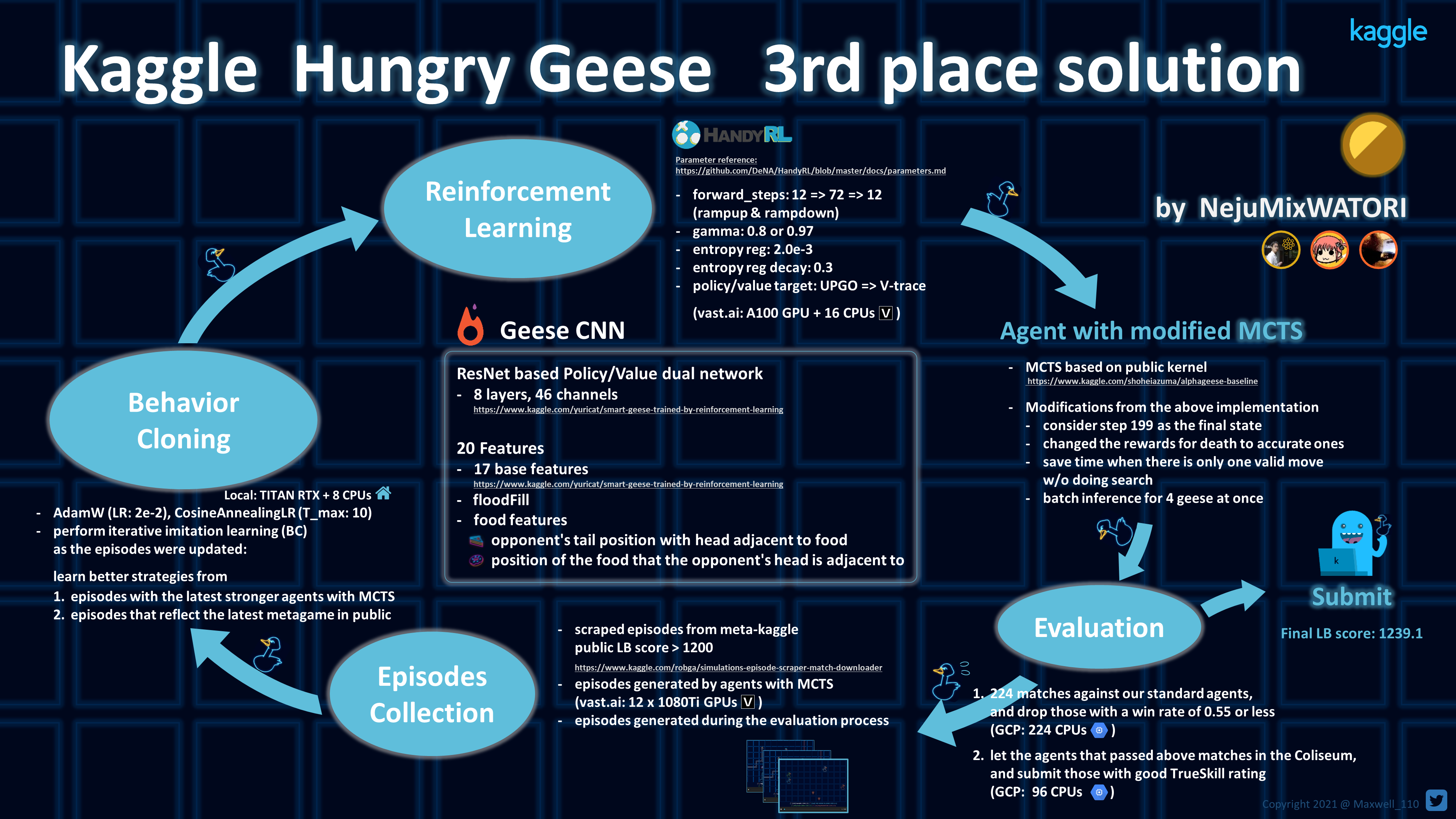
1. 行为克隆 (Behavioral Cloning)
我们收集了高质量的对局并使用这些数据进行预训练。我们使用的对局包括:我们抓取的顶尖智能体的对局、我们团队中使用 GPU 增强搜索的最佳智能体的对局,以及在智能体评估过程中生成的对局。特别是来自顶尖团队的对局被持续收集并反复注入。由于我认为自我博弈的 RL 本质上是一种针对过去自我的“仇恨”方法,我认为通过模仿对手的 RL 在适应元游戏方面会更有优势。除了Public HandyRL notebook中的 17 个特征外,我们还使用了洪水填充和 2 个与食物相关的特征。这些是基于对我们失败对局的观察得出的,目的是封锁糟糕的路径。特征生成过程通过 numba.jit 进行了加速。
2. 强化学习
在 RL 方面,我们严重依赖一个优秀的库——HandyRL。因为我们希望智能体既能学习游戏的长期大局观,又能学习短期效率,我们上下调整了 forward_steps 并相应改变了 gamma,不过目前尚不清楚这是否奏效。对于目标值,我们在大部分训练中使用了 UPGO,并在最后切换到 V-trace 进行重新训练。这是因为使用 UPGO 存在偏差并扭曲了分布,因此校正是必要的。
3. MCTS
它是基于 sazuma 的优秀公开 notebook,但进行了许多改进。改进之处如上图所示,但主要是为了更准确地处理输出值。此外,通过将 step199 正确视为最终状态,我们获得了比预期大得多的提升。因为 step199 不需要模型推理,所以可以显著增加对 step199(以及 198 和之前的步骤)的搜索。
4. 评估
评估非常困难,因为使用 MCTS 进行一局游戏需要很长时间。另一个困难是 LB(排行榜)的初始评估不稳定且收敛缓慢。评估分两个阶段进行:第一阶段,与我们的标准智能体(~LB1200)进行 224 场比赛,结果良好的智能体被加入匹配池,重复比赛以通过 TrueSkill 评估等级。TrueSkill 评级的目的在于通过让我们的智能体接触多样化的策略来评估鲁棒性。评估结果显示在团队的 Slack 上作为 LB。同时,此过程的目的之一是通过大量比赛收集带有 MCTS 的对局。
5. 对局收集
除了从 meta-kaggle 抓取和在评估期间生成对局外,我们还使用 GPU 通过 MCTS 生成对局。由于搜索次数多得多,启用 GPU 的智能体在基准测试结果中更强,使用该对局进行预训练使 LB 评分提高了约 20-30。