第6名解决方案
感谢主办方举办了如此有趣的比赛。
在这次比赛中,我使用了很棒的 HandyRL 库。
与其他库相比,它的代码更容易阅读和学习。
1. 输入
我使用了如下所示的3个输入。

2. 模型
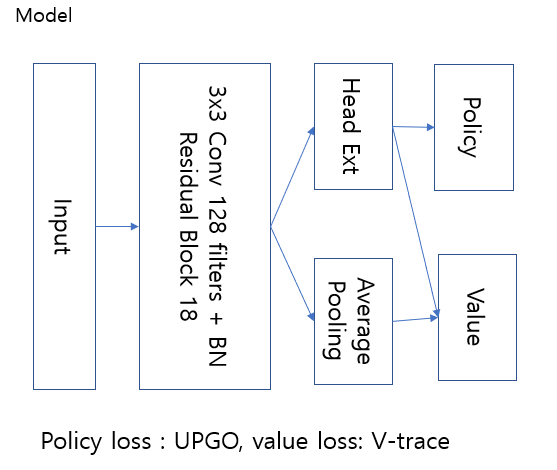
3. 集成与后处理
我对排行榜(LB)前3名模型的输出求和后进行了 argmax 操作。
如果当前动作与上一个动作方向相反,则在 argmax 时排除该动作。
4. 验证与提交
对于每个检查点,与1个模仿学习代理和2个公共代理“Smart Geese Trained by Reinforcement Learning”进行100场对局。
分数规则为:第1名 +5分,第2名 +1分,第3名 -1分,第4名 -5分。
在每天的新检查点中,提交验证得分总和最高的那个。