第5名方案:GeeseZero
我要感谢Kaggle的工作人员以及所有参赛者,带来了如此精彩和激动人心的比赛。
我的方案基本上与传统的AlphaZero方法相同,包括策略网络和价值网络,但使用了一种不同的探索函数,并且向CNN模型输入了许多特征。实现代码在此:https://github.com/takedarts/hungry-geese。我的实现没有使用任何额外数据,如其他玩家的游戏记录或预训练模型。此外,我的实现没有使用任何强化学习框架。
1. 强化学习
强化学习的过程与AlphaZero相同。首先,通过自我对弈生成游戏记录。接下来,使用生成的游戏记录训练新模型。之后,通过对弈评估训练好的模型,并选择最强的模型作为下一步自我对弈的模型。
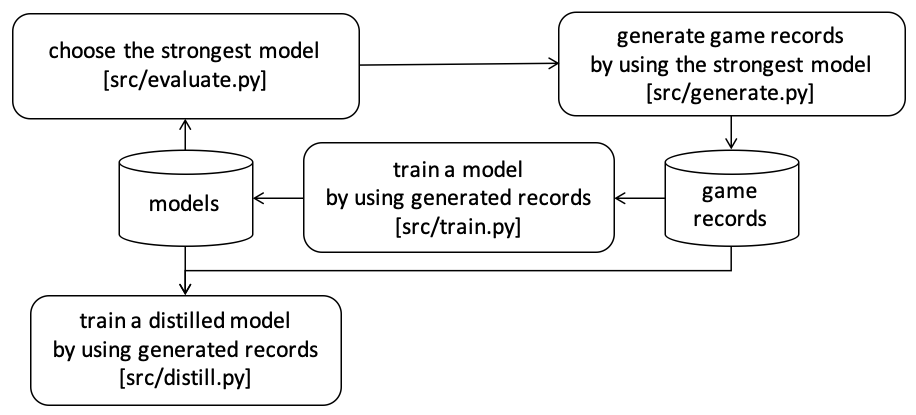
在生成游戏记录的阶段,只使用拥有最强模型的一个智能体。在每一步,该智能体构建一个搜索树来决定所有玩家的移动。这个过程比使用4个智能体的游戏模拟快4倍,但每只鹅可以选择有效的移动来避免碰撞,因为这只鹅知道其他鹅的移动。因此,采用了一种移动到潜在碰撞段的惩罚机制,以强制鹅避开潜在的碰撞段。在比赛期间,使用Threadripper 3970X生成了大约35万条游戏记录。
在训练时,使用最近的6万条游戏记录来训练CNN模型。在这里,食物会从输入特征中被随机移除。在树搜索中,会出现一些食物已经被吃掉的地图,因为树搜索模拟了鹅未来的移动。因此,CNN模型需要在食物已被移除的地图上进行训练。
2. 多头卷积神经网络
在我的实现中,残差卷积神经网络被用作策略和价值网络。输入特征通过以下过程制作:
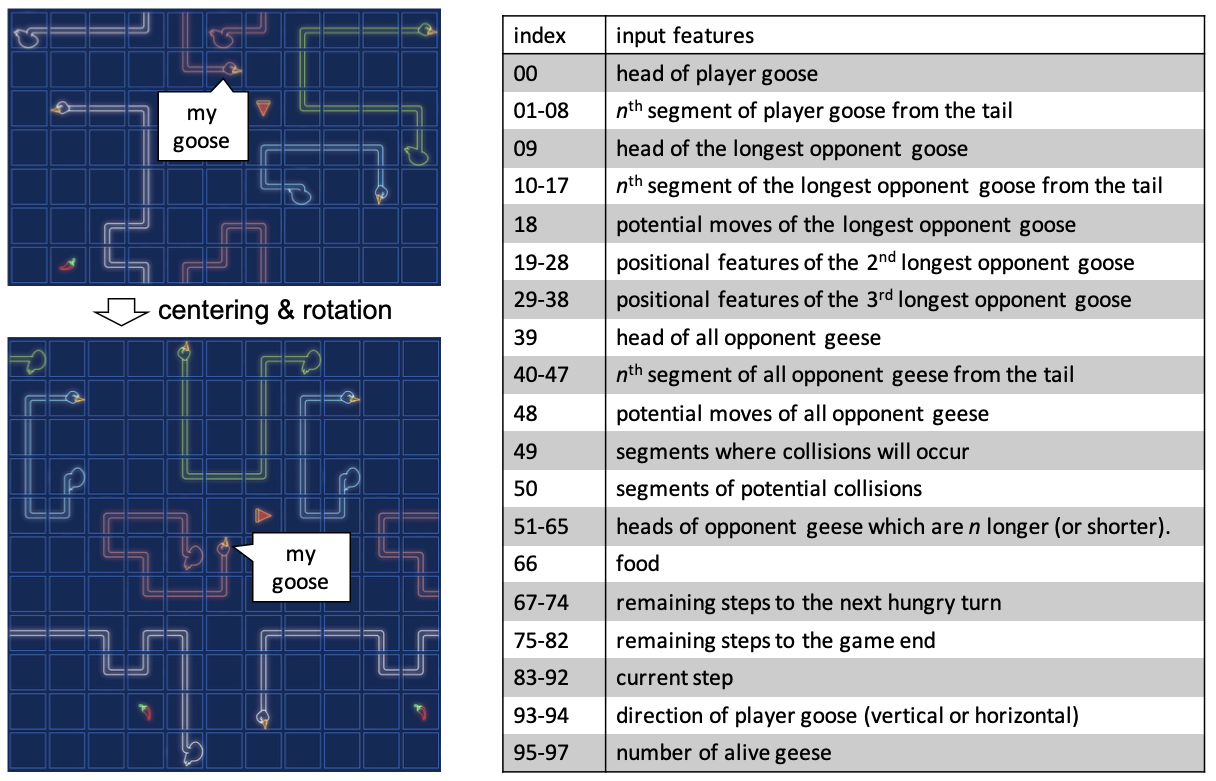
(1)平移地图,使玩家头部位于中心,
(2)旋转地图,使玩家朝向北,
(3)将地图转换为输入特征数组。
输入特征数组的大小为 98 x 11 x 11。输入特征的细节如下图所示。
CNN模型由一个主干块、8个残差块和2个头块组成。首先,主干块将输入特征转换为 64 x 7 x 7 的特征图。然后,残差块将特征图转换为相同尺寸的特征图。这里的每个残差块都是一个包含位置嵌入层的预激活残差块。最后,头块根据残差块转换的特征图生成策略和价值输出。
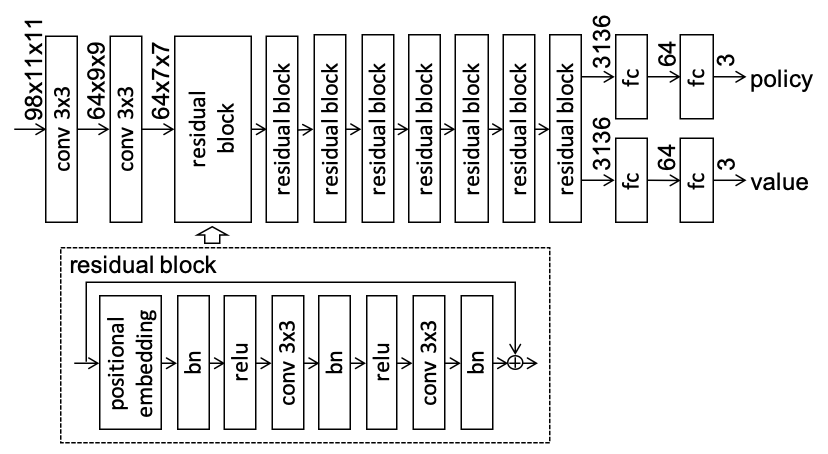
CNN模型的输出是3个策略输出和3个价值输出。策略输出是左转、直行和右转的概率。价值输出是第1名、第2名和第3名的概率。策略输出或价值输出的激活函数是Sigmoid,损失函数是均方误差。
3. 树搜索
我实现中的树搜索算法是解耦置信上限树(Decoupled Upper Confidence Tree: DUCT),这是一种用于同时行动博弈的类MCTS算法。通常,UCB1被用作DUCT或MCTS的探索函数。然而,在我的实现中,UCB1的性能似乎并不好。因此,我使用了一种不同的探索函数:
$$\frac{v_r p_i + \sum_k v_{ik}}{(1 + n_i)^{\frac{3}{2}}}$$
其中 \(v_r\)、\(v_{ik}\)、\(p_i\)、\(n_i\) 分别是父节点的价值、跟随节点 \(i\) 的后代节点的价值、子节点 \(i\) 的策略、子节点 \(i\) 的访问次数。我的探索函数考虑了策略,但价值对节点选择的影响大于策略。
每个节点的价值被归一化为:
$$\sum_p v_{ip} = 1$$
其中 \(v_{ip}\) 是节点 \(i\) 处玩家 \(p\) 的价值。由于这种归一化,我的智能体不仅为了生存而移动,还会猎杀其他鹅。
4. 启发式算法与参数
我的实现包含一个简单的用于检测死胡同的前瞻搜索。但是,该搜索算法不预测其他玩家的移动,因此前瞻搜索仅用于过滤掉通向明显死胡同的移动。
我的智能体有几个决定智能体特性的参数。
- collision:移动到潜在碰撞段的惩罚。
- eating:吃食物的奖励。
- safe:增加此项时,智能体以生存为目标而非追求第一名。
- <strong