第一名解决方案:Team Isamu & Matt
感谢 Kaggle 和 ASHRAE 举办了这次比赛。决定在私有测试集中仅使用非泄露数据有助于使这次比赛更加公平。感谢所有为内核和讨论做出贡献的人,特别是那些公开泄露数据的人。最后但同样重要的是,我要感谢并祝贺我的队友 Isamu Yamashita,他是一位很棒的队友,并成为了 Competition Master。
在比赛期间,我们在团队内部分享想法并讨论进展,但我们测试和训练了分开的模型。这有助于我们在最终集成中保持多样性。这是我们团队解决方案的综合总结。
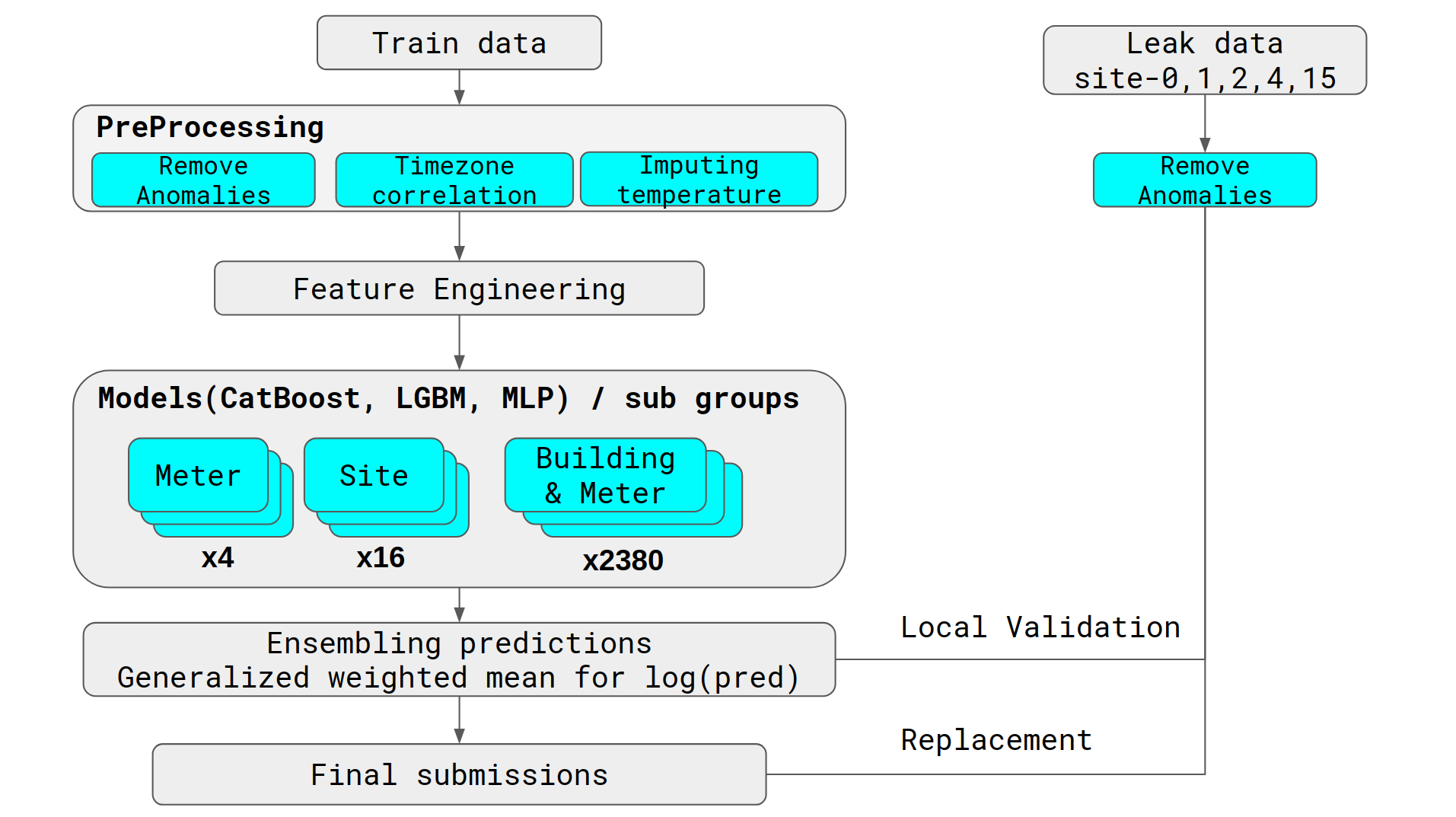
预处理
移除异常值
正如其他人所指出的,清洗数据在这次比赛中非常重要。假设是数据中存在不可预测且因此无法学习的异常值,如果对其进行训练,会降低预测质量。我们识别并过滤了三种类型的异常值:
- 长时段的恒定值
- 巨大的正/负峰值
- 通过目视检查确定的其他异常值
我们注意到其中一些异常值在一个站点(site)的多栋建筑物中是一致的。我们使用站点中的所有建筑物验证了潜在的异常值——如果异常值在同一时间出现在多栋建筑物中,我们可以合理地确定这确实是一个真正的异常值。这使我们能够移除那些不一定属于长时段恒定值或巨大峰值的异常值。
插补缺失温度值
温度元数据中有大量缺失值。我们发现使用线性插值来插补缺失数据有助于我们的模型。
本地时区校正
正如比赛论坛中所指出的,训练/测试数据中的时区与天气元数据中的时区不同。我们使用了这篇讨论帖中的信息来校正时区。
目标转换
像大多数竞争对手一样,我们首先预测 log1p(meter_reading)。我们还根据这篇讨论帖校正了站点 0 的单位。
在比赛接近尾声时,我们尝试通过除以 square_feet 来标准化 meter_reading;即我们预测 log1p(meter_reading/square_feet)。Isamu 在阅读了 Artyom Vorobyov 的这篇讨论帖后提出了这个想法。使用标准化目标训练的模型增加了我们最终集成的多样性,并将我们的分数提高了约 0.002。如果我们有更多时间,我们会想进一步探索这个想法;例如,我们可以尝试预测 log1p(meter_reading)/square_feet 或使用标准化目标创建特征。
特征工程与特征选择
在这次比赛中,我们在特征工程和特征选择上采取了不同的方法。Isamu 采取了保守的方法并仔细选择了特征;另一方面,Matt 采取了蛮力的方法并使用了大部分特征。以下是有帮助的特征:
- 来自训练/测试、天气元数据和建筑物元数据的原始特征
- 分类交互,例如
building_id和meter的拼接 - 时间序列特征,包括假日标志和一天中的时间特征
- 计数(频率)特征
- 类似于公共内核中的滞后温度特征
- 使用 Savitzky-Golay 滤波器的平滑和一阶、二阶微分温度特征(见下图)