第5名方案
首先,我们要感谢 Kaggle 和 ASHRAE 团队举办了这次比赛!
很抱歉,由于我的懒惰,帖子发晚了。
我们的方案并不复杂,我认为还有很多改进的空间。
(我想提前道歉,我在日常生活中不使用英语,所以我的英语不好)
以下是我们方案的概述。

预处理
我们删除了以下行:
- 长时间恒定值的连续数据
- 零目标值(仅限电力)
通过移除这些数据,分数得到了显著提高。
特征工程
我们尝试了两种目标编码。
1. 每个 building_id 和 meter 的百分位数
如图所示,计算每个 building_id 和 meter 的目标值的第 5 和第 95 百分位数,我们使用了这些特征。
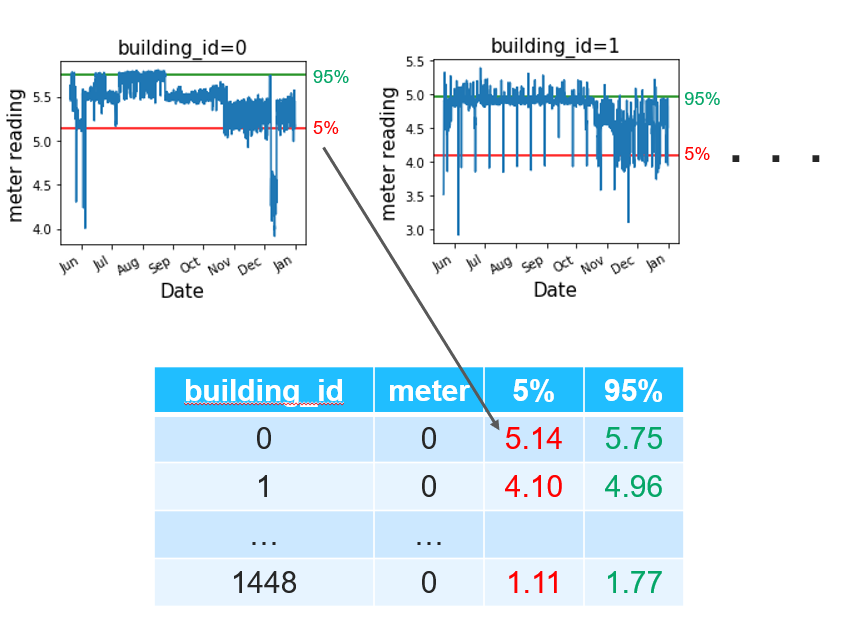
在我们的案例中,这些特征提高了分数。
2. 比例
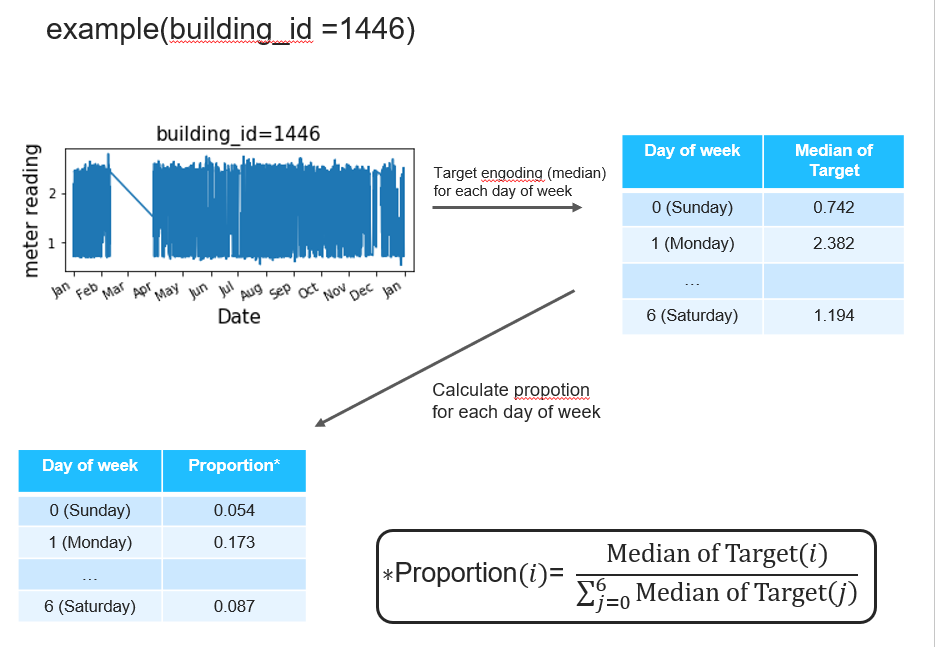
对于每个 building_id,我们应用以下过程:
- 计算每周几的目标值中位数。
- 计算其比例(见图)。
这是“星期几”的一个例子。我们也把这种技术应用于小时、天等。
建模
- 仅使用 LightGBM(针对每个 meter 进行训练)
我们应用了两步建模法:
第一步:确定每个 building_id 的 num_boost_round
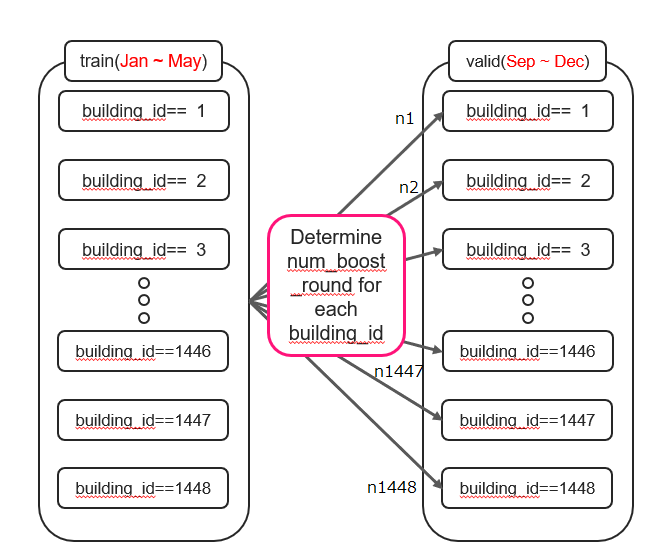
- 定义训练数据(2016/01/15 ~ 2016/05/31)和验证数据(2016/09/01 ~ 2016/12/31)。
- 使用 LightGBM 进行训练,并为每个 building_id 找到早停轮次(n1 ~ n1448)。
第二步:使用所有训练数据(2016年)进行训练并预测测试数据
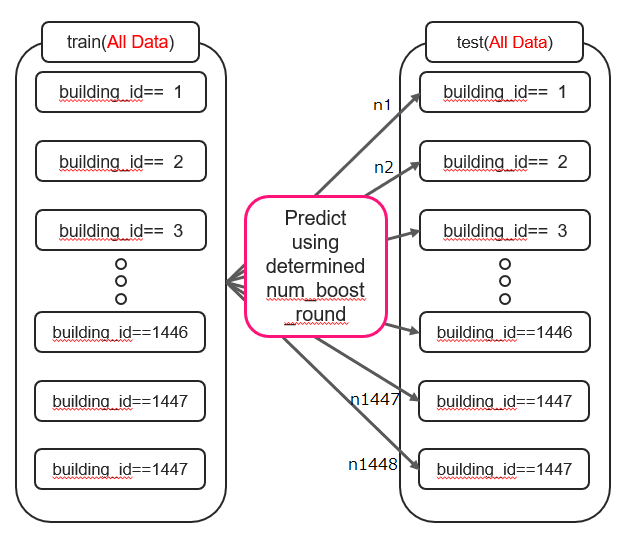
使用所有训练数据进行训练并预测测试数据。用于预测的树的数量针对每个 building_id 进行了更改(使用第一步中获得的 n1~n1448)。
这种方法提高了 Public LB 分数,但 Private LB 分数提高不多。
模型融合
- 使用了泄露数据(site 0, 1, 2, 4, 15)。
- 针对每个 meter 和年份(2017, 2018)进行加权平均。
我们也使用了其他参赛者的提交文件:
提交结果
融合后,我们在 Public LB 上达到了 1.047,Private LB 上达到了 1.236。
(我们的单模型在 Public LB 上为 1.058,Private LB 上为 1.272)