第二名解决方案
我们的团队在 Private LB 上获得了第 2 名(Public LB 第 12 名)。Private LB 终于正式发布了。
非常高兴和激动,这是我在 Kaggle 上第一次赢得奖金(经过 6 年的努力)。圣诞老人今年很仁慈 :-) 我们团队也会很友善地分享我们的完整解决方案。
解决方案架构:
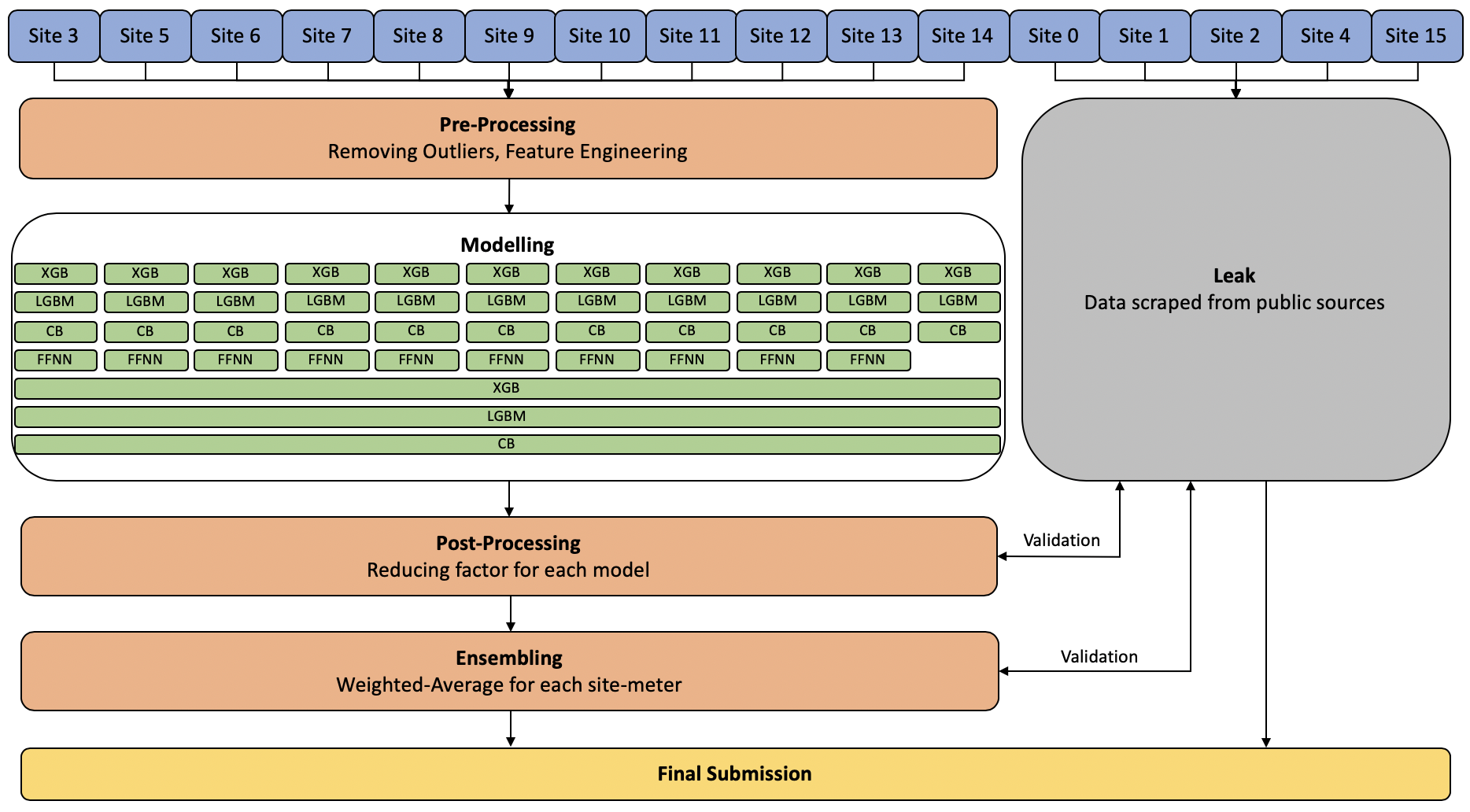
XGB: XGBoost
LGBM: LightGBM
CB: Catboost
FFNN: 前馈神经网络
简述
- 移除噪声(非常重要)
- 非常少且基础的特征(为了稳定性)
- 针对每个 site+meter 优化模型(为了捕捉特定地点的模式)
- XGBoost, LightGBM, CatBoost, 神经网络的集成(为了降低方差)
- 后处理(非常关键)
- 泄露数据插入(虽然很糟糕,但可能无关紧要)
最终集成(近似): 30% XGB-bagging + 50% LGBM-bagging + 15% CB-bagging + 5% FFNN
我们对 XGB, LGBM, CB 的多种变体进行了装袋:包括在 site+meter 级别、building+meter 级别、building-type+meter 级别。在所有提升方法中,装袋后的 XGB 给出了最好的结果。
FFNN 仅用于 meter = 0。它在其他仪表上结果很差,没有为集成增加价值。此外,FFNN 在 site-14 上表现非常差,所以我们没有使用它,因此架构图中的模型部分缺少了那个板块 :-)
我们的解决方案很大程度上建立在 @oleg90777 的基础 XGB/LGBM 设置之上(在没有泄露的情况下 LB 分数为 1.04),我们的关键点是清理数据和后处理预测(在泄露数据和 LB 上验证)。更多内容请阅读这里。
最终的集成在 Public LB、泄露数据以及 Private LB 上几乎都取得了最好的成绩,希望它是稳健且有用的。
详述
预处理
目标变量的许多低值似乎是噪声(正如论坛中多次讨论的那样,特别是针对 site-0),从训练数据中移除这些行可以显著提高分数,其他几位参赛者也这样做过。
这是最耗时的任务,因为我们可视化了每个建筑并编写代码手动移除这 1449 个建筑的行。我们可以使用一套启发式规则,但由于一些边缘情况,这并不是最优的,所以我们决定在每个建筑上花几分钟时间来移除异常值。
特征工程
由于数据集的规模庞大以及建立稳健验证框架的困难,我们没有过多关注特征工程,担心它可能无法干净地外推到测试数据。相反,我们选择集成尽可能多的不同模型,以捕获更多信息并帮助预测在年份之间保持稳定。
我们的模型几乎没有使用任何滞后特征或复杂特征。我们最好的单一模型中只有不到 30 个特征。这是我们在工作开始时做出的主要决定之一。根据过去的经验,如果没有可靠的验证框架,构建好的特征是很棘手的。
建模
我们在不同的数据级别上装袋了一堆提升模型 XGB, LGBM, CB:针对每个 site+meter 的模型,针对每个 building+meter 的模型,针对每个 building-type+meter 的模型以及使用整个训练数据的模型。为每个站点建立一个单独的模型非常有用,这样模型可以捕捉特定站点的模式,并且每个站点可以安装适合它的不同参数集。它还自动解决了诸如时间戳对齐和不同站点特征测量尺度不同的问题,因此我们不必单独解决它们。
在不同级别集成模型有助于提高分数。仅仅使用不同的种子进行装袋并没有太大帮助。
站点级别的 FFNN 仅用于 meter = 0。每个站点有不同的 NN 架构。它在其他仪表上结果很差,没有为集成增加价值。此外,FFNN 在 site-14 上表现非常差,所以我们没有使用它,因此架构图中的模型部分缺少了那个板块 :-)
对于所有模型的调优,我们结合使用了训练数据上的 4 折和 5 折交叉验证(按月份)以及对泄露数据的