显性COT+隐性COT如何高效压缩长思维链
团队介绍
- 颜子涵:就职于蚂蚁集团
- 于战锋:北邮研三在读,蚂蚁集团实习生
赛题背景
在金融领域,风险评估、财务审计、合规检查等核心业务往往需要复杂且多步的逻辑推理,涉及法律、财务、经济等多学科知识的综合运用。为确保推理准确性与可解释性,当前大型语言模型普遍依赖冗长的思维链(Chain-of-Thought, CoT)进行推理。然而,过长的推理过程不仅增加计算资源消耗与响应延迟,还可能引入不必要的噪声,影响模型在实际业务中的部署效率与应用价值。
本赛题旨在探索长思维链的高效压缩方法,在保留关键逻辑与高准确率的前提下,减少冗余内容、优化推理路径,从而提升模型在金融场景下的推理效率与响应性能。题目涵盖表格推理、计算推理、逻辑推理等多类金融复杂问题,模拟跨文档理解、规则计算及跨学科知识整合的真实业务需求,为模型在金融及其他高精度行业的落地应用奠定技术基础。
赛题理解
语言是思维的枷锁,纯粹的推理必将超越语言的局限。
DeepSeek和O1等模型最近非常火热,因为他们能解决更深层次的数学/代码/逻辑问题,在GSM8K、MATH等评测集上有直观的表现。现有的算法模型生成COT的思路都是通过文字表达,我们称这个过程为"显式COT"。目前非常多的实验证明大模型在思考的过程中,并不一定依赖"显式COT"的内容,例如在数学题场景下,可能中间过程错了,但是最终答案还是对了。是否大模型只是需要一个计算过程?而不是显式的文字。
所以我们计划提出"隐式COT"的概念,是否用一个embedding就能代表整个计算过程?这个概念类似于BERT时代的Ptuning和PAT。例如Meta的经典工作Coconut,Coconut模型的结论是:"隐式COT"的效果 > "显式COT"。这个实验结果从encoder seq2seq到GPT实验都在不断被验证,从理论上来说是必然。
但是Coconut并没有对隐式COT进行压缩。
基于Coconut的实验结果,产生了很多有趣的压缩"隐式COT"的方案,例如近两年LightThinker、DART、CODI、EoOT等;但是目前所有关于隐式COT的方案包括Coconut都是输出隐式COT后直接输出答案。隐式COT完全黑盒。
目前已经有paper支持一些观点:
- Transformers除了next-token的能力,未来多个token也能预测
- Offline-RL在数学相关领域有非常强的作用
- RL对于隐式COT的感知并不强,对显式COT的感知很强(有具体数字)
所以我们试图提出一种框架,既能用隐式的COT压缩token,提升能力。同样也可以基于隐式的COT进行"翻译",输出显式的COT。通过SFT和RL先根据隐式COT输出结果,再输出显式COT。
这样做有两个好处:
- 输出结果后不需要等到显式COT,可以直接截断LLM输出。第一时间得到数学结果;
- RL可以结合显式COT进行训练。
本赛题可以看作是金融领域的数学题,我们试图去发现一种更巧妙的方法去解决它,尤其是适用于math和逻辑推导领域。我们的目的是:少量的隐式COT能够解决完整的金融数学问题。
算法设计
我们首先需要解决的是隐式COT如何和显式COT在金融数学领域完全对等?最直观的方式是attention意义上的恒等,也就是隐式COT的attention数值能够完全被显式COT代替。只需满足下列表达式:
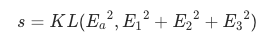
(E为token embedding,推导略)
但是这种方式效果并不理想,从机理上猜测,Transformer的MHA并不是每一层都关注attention值,Transformer内部更多的是黑盒。除了attention值外。所以我们在非常宏观的角度去寻求这种对等意义。
于是我们希望在语义层面,隐式COT和显式COT完全对等。
例如下图,思考的部分都用<think_i>代替,所有的解释都放在最后。推理的时候遇到<end>就可以结束,<explain>后面是隐式COT的显式解释。其中7、6是我们认为不可隐示的核心中间结果。

核心算法
如样例图所示,我们希望<think_1>尽可能的和"Janet started with 10 apples. She gave away 3, so 10 - 3 = 7 apples."等价。
最简单的方案就是我们在训练的时候加入一个约束,让隐式COT和显式COT在欧氏空间中的物理意义相同,我们假设隐式COT<think_i>对应的显式COT是seq_i:
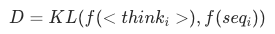
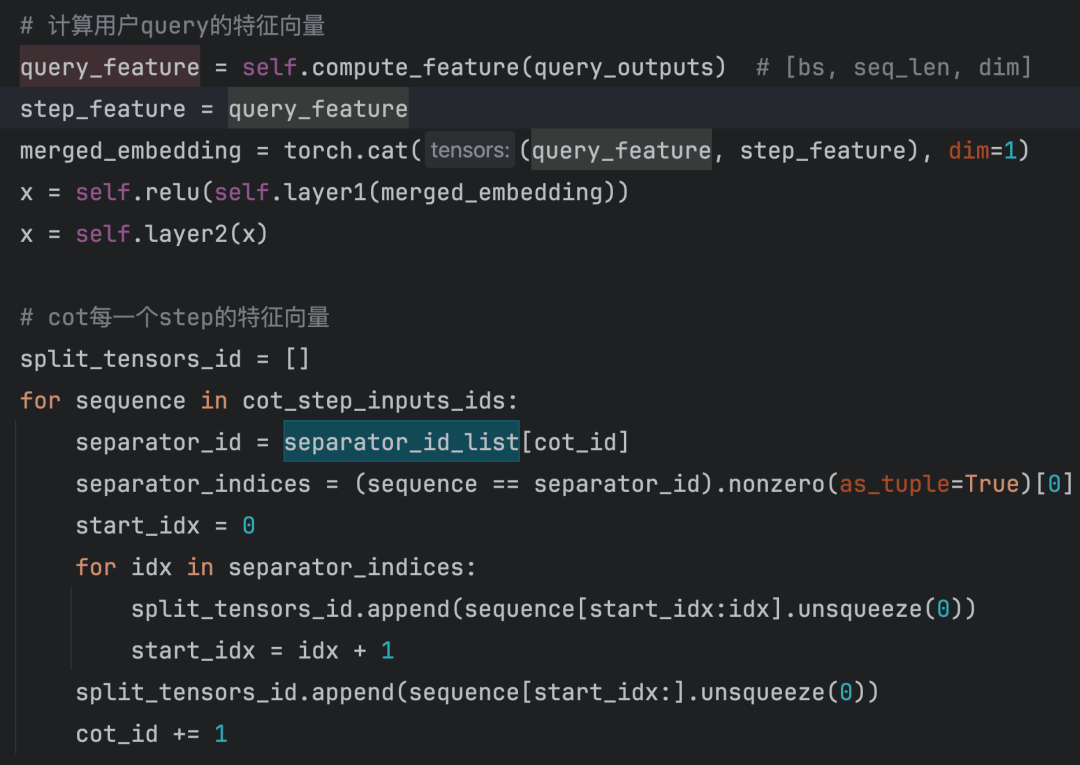
核心代码:
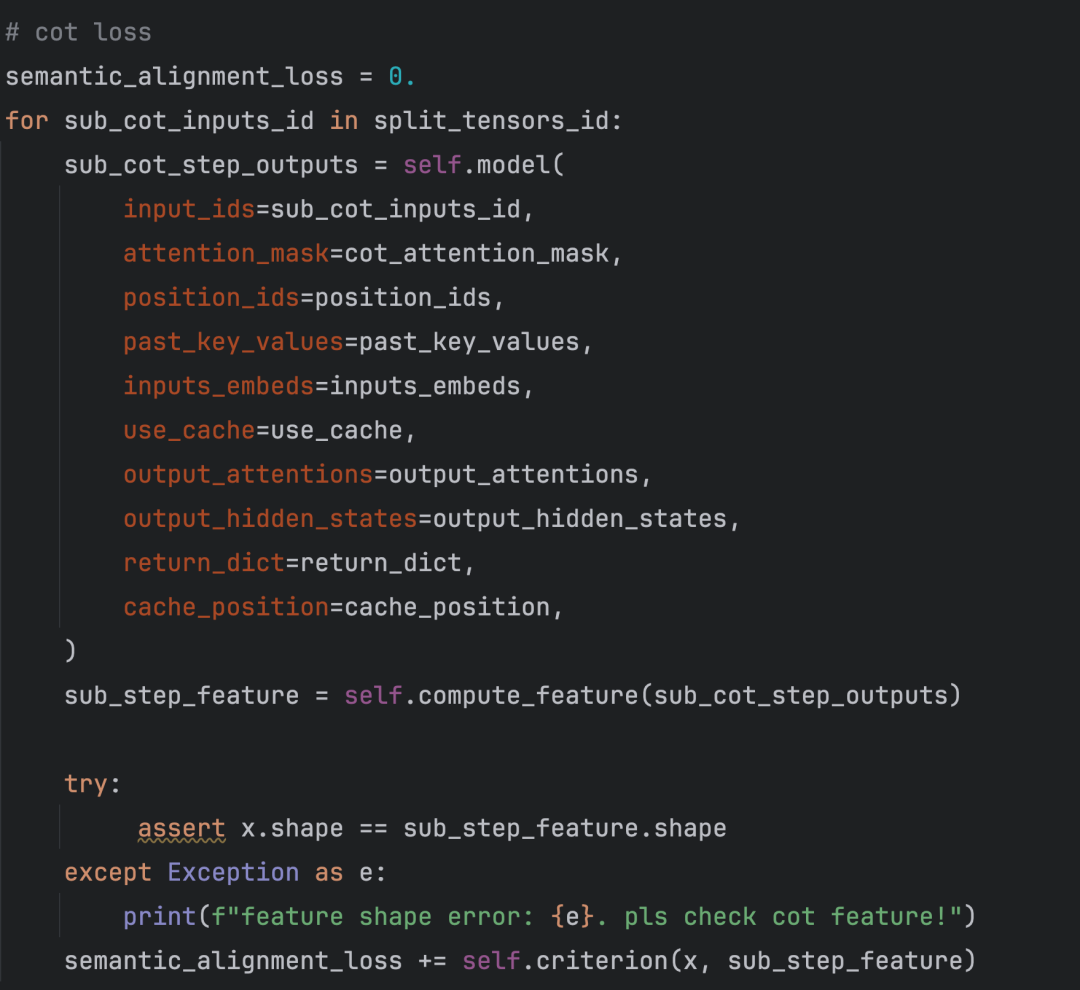
其中f(.)是向量化的工具。为了和保持训练的对齐,我们采用Qwen-4B进行了向量化。但是会引来新的问题,如果<think1> <think2>仅仅是词表中新增的特殊token那么训练一定会崩溃。因为<think_i>本身就不应该是固定的语义。是需要随着用户query变化而COT变化的。这里我们尝试了两种做法:
- 第一种是训练的时候直接把think的这部分loss mask掉,训练不感知;
- 第二种是:
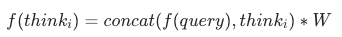
核心代码:
最终的目标函数:
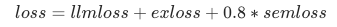
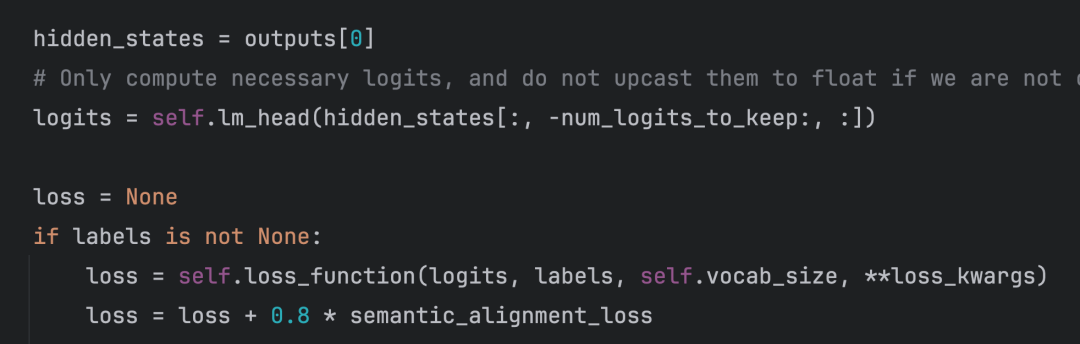
其中LLM loss和exloss都包含在了代码块的loss里面。
训练数据
我们的训练数据是采用LLM进行构造的。首先我们利用O1对GSM8K, GSM8K-HARD,AIMO等数学数据集上构造了5万条训练样本。通过O1构造了10万条金融相关的数据集。数据中包含的内容有拆分的子step,以及模型认为的关键计算结果。
数据样例:
{
"source": "synthetic_math",
"problem": "Find all solutions to the equation $\\displaystyle\\sqrt[3]{3 - \\frac{x}{3}} = -2$.",
"solution": "Start by isolating the cube root:\n$$ \\sqrt[3]{3 - \\frac{x}{3}} = -2 $$\n\nCube both sides to eliminate the cube root:\n$$ 3 - \\frac{x}{3} = (-2)^3 $$\n$$ 3 - \\frac{x}{3} = -8 $$\n\nSolve for $x$:\n$$ 3 + 8 = \\frac{x}{3} $$\n$$ 11 = \\frac{x}{3} $$\n$$ x = 33 $$\n\nThus, the solution to the equation is:\n$$ \\boxed{x = 33} $$",
"cot": {
"step1": "Start by isolating the cube root: \\( \\sqrt[3]{3 - \\frac{x}{3}} = -2 \\)",
"step2": "Cube both sides to eliminate the cube root: \\( 3 - \\frac{x}{3} = (-2)^3 \\)",
"step3": "Simplify the right side of the equation: \\( 3 - \\frac{x}{3} = -8 \\)",
"sub_result": "The simplified equation is: \\( 3 - \\frac{x}{3} = -8 \\)",
"step4": "Solve for \\( x \\): \\( 3 + 8 = \\frac{x}{3} \\)",
"step5": "Combine like terms: \\( 11 = \\frac{x}{3} \\)",
"step6": "Multiply both sides by 3 to isolate \\( x \\): \\( x = 33 \\)",
"result": "\\( x = 33 \\)"
}
}
课程学习策略
按照上述的金融数据例子,我们将数学公示压缩的更小了。但是我们发现这或许并不是它的极限。正如开始的时候说的,部分经常LLM会出现中间结果错误,但是最终结果正确。我们发现中间结果在最开始训练的时候非常关键,但是在后面训练过程中并不关键。
我们采用以下两种方式进行数据配比,进行了课程学习:
- 我们根据COT的step数量进行了排序。优先让模型训练较少step的数据,然后逐渐扩大step数量;
- 开始的时候子结果很多。然后逐渐减少子结果。直到最后没有。
除此之外我们还对数据进行了去重,数据的长度排序以及质量打分。
强化学习训练
我们基于结果进行了GRPO/DAPO的尝试,基于过往的经验,这里我们舍弃了KL散度的部分:

除了比赛的数据集外,我们之前在实验中(基于Llama3-1B)在多个数学数据集上也做了验证。
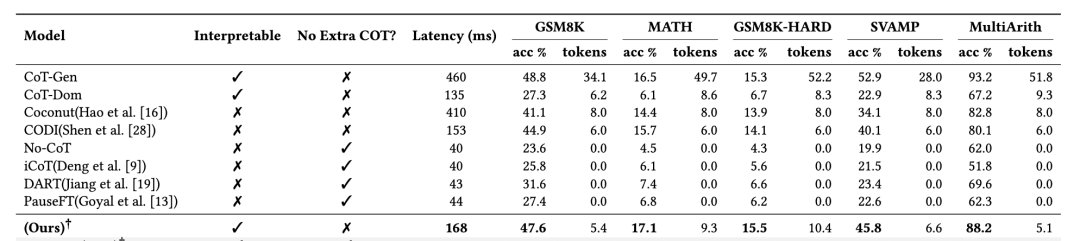
我们也对RL和去除中间结果{Intermediate Calculation Results} (ICR) {AE} (Answer-only without Explanation)的部分做了消融:
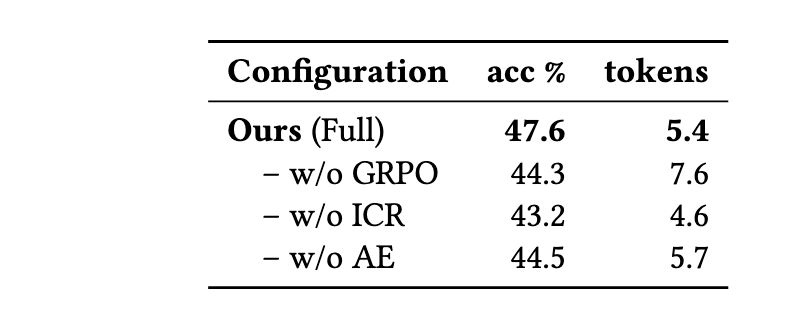
比赛实验结果
在比赛的实验中,我们首先获取了初赛的label作为实验标签。
获取方式:我们通过DeepSeek, Qwen3-235B, GPT4O等投票得到了比赛的答案,然后提交了一份原始COT的正确答案。经过对比COT的token数,以及线上的分数,得出我们的答案100%正确。
我们基于Qwen3-4B在大量金融数据和数学数据中训练模型。层次化训练前,最佳成绩在p@1(不使用5次投票)的准确率为86%,平均最佳COT长度token为42。
进行层次化训练后,最佳成绩在p@1(不使用5次投票)的准确率为84%,平均最佳COT长度token为24。
然后我们尝试了蒸馏实验,利用72B充当teacher,4B充当student。这里的蒸馏非常简单,我们仅考虑了logits层面的蒸馏:
(为什么用Qwen2.5,因为在Codefuse相关业务上的经验 Qwen2.5 > Qwen3)
其中得到了4B模型,最好的成绩是在p@1(不使用5次投票)的准确率为89%,控制平均最佳COT长度为17。
其中得到了4B,在p@5(使用5次投票)的准确率为94%,控制平均最佳COT长度为12.4。
最后我们使用初赛的label加入了训练,p@1(不使用5次投票)的准确率为97%,控制平均COT长度为2.1,p@5(使用5次投票)的准确率为100%,控制平均最佳COT长度为1。这个结果提交的分数是-500,是过拟合的。
实验中发现的有趣点
我们公开了基于LLAMA-FACTORY QWEN的SFT部分的代码,由于时间原因没有太多优化。抛出一些我们在其他实验过程中发现有趣的点,希望能和大家多交流:
- 训练loss和semloss的时候,我们尝试过优先训练显式和隐式对齐部分的参数,冻结LLM的其他参数,但是没有效果;
- 上述1没有work,但是通过KL强制语言近似太暴力了,调参的波动很大,收敛不稳定;
- 我们在实验中发现基于ORM-RL训练的部分对<explain>后面的token不是很友好,PRM对<explain>会让后面解释更准确但是效果很差,我们没有发现这个现象的原因;
- 数学中间结果前期训练重要但是在训练的后期并不重要,可以舍弃,尤其是通过课程学习减少中间结果,ACC几乎不会下降。
参考文献
- [1] Dual-Stream Attention Transformers for Sewer Defect Classification
- [2] DART: Distilling Autoregressive Reasoning to Silent Thought
- [3] Stop Overthinking: A Survey on Efficient Reasoning for LLMs
- [4] L1: Controlling How Long A Reasoning Model Thinks
- [5] Sketch-of-Thought: Efficient Reasoning via Cognitive-Inspired Prompting
- [6] Training Language Models to Reason Efficiently
- [7] CODI: Compressing Chain-of-Thought into Continuous Space via Self-Distillation
- [8] DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via RL
- [9] Compressed CoT: Efficient Reasoning Through Dense Representations
- [10] Training LLMs to Reason in a Continuous Latent Space (Coconut)
- [11] From Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step
- [12] DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open LLMs
- [13] PauseFT: Think Before You Speak—Training Language Models with Pause Tokens
- [14] Implicit Chain of Thought Reasoning via Knowledge Distillation
- [15] Graph of Thoughts: Solving Elaborate Problems with Large Language Models
- [16] Reasoning with Sketches: Efficient Intermediate Representation Learning
- [17] Early Exit Strategies for Reasoning Optimization in LLMs
- [18] Think Silently, Think Fast: Dynamic Latent Compression of LLM Reasoning Chains
转发有礼
- 关注 "AFAC2025" 公众号。
- 转发本篇文章到朋友圈+5个技术微信群(100人以上),并截图发到【AFAC2025】公众号后台。
- 先到先得,AFAC公众号后台会私信中奖者提供收货信息。

 ```
```