AFAC 2025 冠军方案解析:金融领域中的长思维链压缩
赛题背景
金融领域的复杂推理任务需要模型执行多步严谨的逻辑推理,综合运用法律、财务、经济等多学科知识。当前大型语言模型虽然具备较强的推理能力,但往往依赖冗长的思维链来保证准确性,导致计算资源消耗大、响应延迟高。那么如何在不降低推理准确性的前提下,优化模型推理路径,高效压缩冗余内容,从而降低资源成本、提升执行效率呢?因此该赛题孕育而出。
赛题分析
比赛数据
为金融领域相关推理问题,问题满足以下条件:
- 问题数量:隐藏测试集100条,公开测试集100条
- 问题难度:比赛指定的Qwen3-4B模型上能够在Bo5设置上正确回答。
- 问题上下文:问题描述中包含解决问题所需要的额外金融知识,包括背景知识、必要概念定义、相应计算规则、具体数据等,确保问题长度不超过2 k token。
- 问题答案:保证问题拥有明确的唯一答案,能够基于规则客观评估正确性。答案不出现在问题当中,并且难以被随机方法猜测出。
- 问题种类:金融领域常见类型推理问题,包括表格推理、计算推理、逻辑推理等。
评分规则
最终以模型在隐藏数据集上的表现作为模型的最终表现。最终评分来源于准确性和高效性两个方面:
- 准确性:方法通过的最低标准为准确率90%。
- 高效性:对每个问题取正确回答sample中的最短模型原始回复长度作为该问题的CoT长度。对于没有正确回答的问题,该问题的CoT长度为预设的最大值12 k。
- CoT可读性(决赛阶段):评估模型CoT部分的质量,维度包括结构性、事实性等。
最终方法得分为所有问题CoT长度的总和的相反数。因此我们需要在保证准确率的前提下尽可能压缩Qwen3-4B推理思维链的token。
具体方案
由于仅依赖提示词方法以4B的基础知识能力有部分题哪怕如何思考都无法给出正确答案,因此需要进行蒸馏,而A榜测试集仅100条,直接微调必然会导致强烈过拟合,而对未见的隐藏B榜测试集泛化能力极差,因此显而易见的需要进行数据增强。由此我们提出了基于多阶段压缩与自一致性偏置解码的思维链优化方案。
整体框架
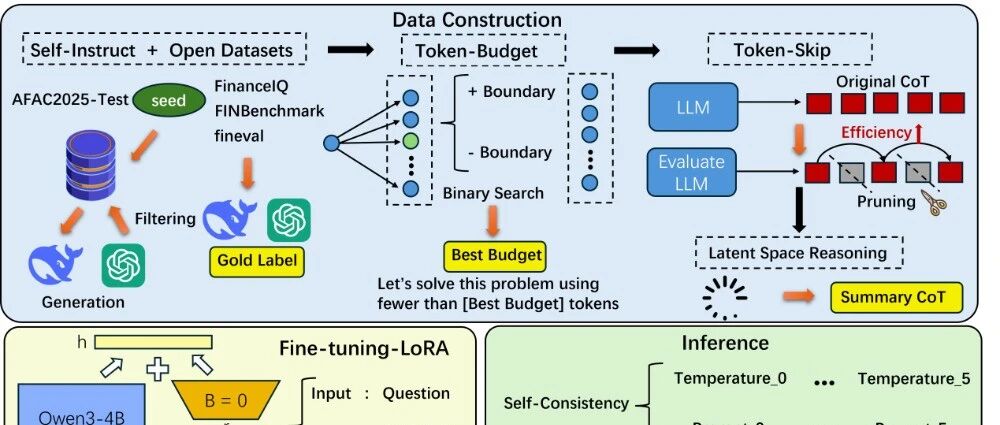
主要通过数据增强、多阶段压缩、高效微调和推理优化四个环节,实现了思维链的高效压缩。
数据增强
我做了两步走的数据增强,第一步是通过Self‑Instruct利用大模型自身高效自动化的进行数据生成,首先是把100条测试集作为种子数据放入到数据池中,然后在数据池中随机选择k条数据作为示例,以上下文学习的范式让大模型去生成类似的数据样本,然后再通过ROUGE‑L对相似样本进行去重并且通过长度过滤低质量的数据,然后把过滤后的样本添加到我们的数据池,然后再循环往复直到达到我们设定的数据量。
然后第二步的数据增强则是寻找开源的金融领域的Benchmark数据集,这种用来评测模型性能的榜单数据质量肯定比自己合成的要高很多,这里我们找了三个不同的Benchmark,然后通过Python和正则表达式将这三份不同数据规范的数据转换成统一格式,而且值得注意的是,FinEval中的验证集已经为每个答案提供了一个高质量的思维链解释,且平均长度仅为66,这个长度也为我们之后思维链到底要压缩到什么程度提供了一个参考标准。
多阶段压缩
Token‑budget

简单来说就是通过对每个问题给出最优的能够解决该问题的Token预算来实现思维链压缩。问题来了,怎么得到这个Token‑budget预算呢?论文给出的方法是使用二分,比如我们一开始的思维链长度是1024,那提示词就是思考不超过512个token,如果能解决,就继续往下,256,128,时间复杂度是O(log n),完全能接受。然后得到了最好的Token预算,则加入到提示词中进行第一阶段的思维链压缩。
Token‑skip
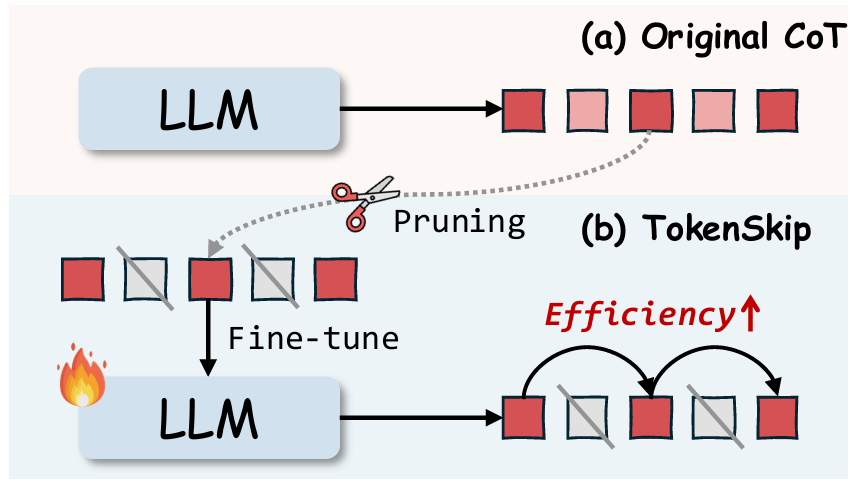
我们将上一阶段Token‑budget得到的初步压缩后的思维链再通过Token‑skip这个方法进行第二阶段的压缩,具体来说通过一个训练的评估器对每个Token进行重要性评分,修剪不重要的冗余Token来实现第二阶段的压缩。值得注意的是,基于压缩后的思维链通过扩写能够进行还原,表明该过程信息损失较小,也就是说压缩后的思维链是高质量的、具有可解释性的。并不是说随便裁剪,剪的语义都不通顺了,是可以进行一个还原操作的。
Latent space reasoning
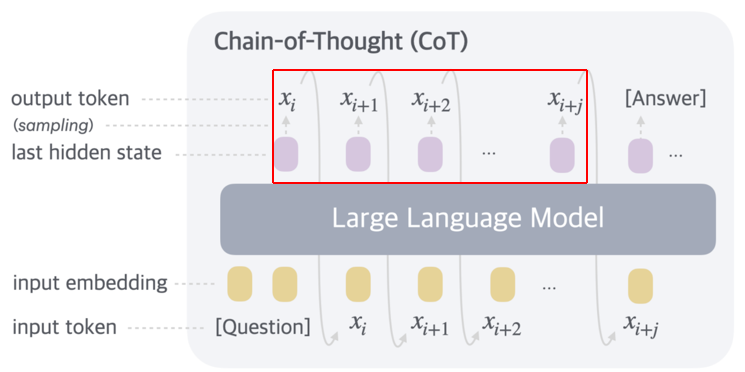
然后是第三阶段的思维链压缩,通过Latent space reasoning对第二阶段的进行一个总结,这是压缩效率最高的一个方法。与传统的显式思维链不同,潜空间推理是在模型内部的高维隐藏层中的状态中展开的,尽管同样在思考但无需显式思维链token。
高效微调
然后是高效微调部分,我们把构建好的经过三阶段压缩的数据集去LoRA微调Qwen3‑4B。选择LoRA而不是全参的原因有两个:一是防止过拟合,保证B榜有更好的泛化性;二是效率高,几个小时就能微调完,这样就能通过不断的调参lora_rank、lora_alpha、learning_rate等等,选择一个较好的模型然后去刷榜。
推理优化
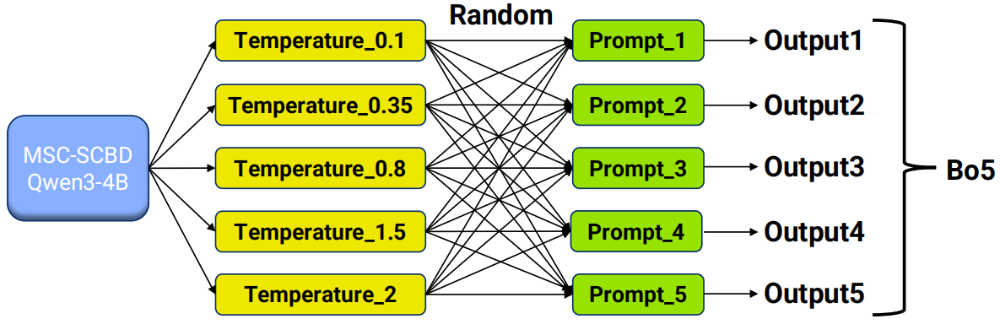
恰好赛题要求了Bo5且对每个问题取正确回答sample中的最短模型原始回复长度作为该问题的CoT长度,因此利用Self‑Consistency方法去随机混合不同的Temperature和Prompt进行交叉推理,保证答案的准确性。此外,我们在推理阶段还通过Logit Bias进行底层干预,直接修改模型预测的原始logits分数,这样就可以在推理阶段抑制某些Token,尤其是符号类,比如换行符等等,进一步压缩思维链长度。
总结
我们提出的多阶段压缩与自一致性偏置解码框架,在金融领域长思维链压缩任务中表现出色。该方法不仅适用于金融领域,还具有向法律、医疗、工程等高精度需求场景迁移的潜力。代码已经开源在GitHub上。
参考文献
- [1] Wang Y, Kordi Y, Mishra S, et al. Self‑instruct: Aligning language models with self‑generated instructions[J]. arXiv preprint arXiv:2212.10560, 2022.
- [2] Han T, Wang Z, Fang C, et al. Token‑budget‑aware LLM reasoning[J]. arXiv preprint arXiv:2412.18547, 2024.
- [3] Xia H, Leong C T, Wang W, et al. Tokenskip: Controllable chain‑of‑thought compression in LLMs[J]. arXiv preprint arXiv:2502.12067, 2025.
- [4] Zhu R J, Peng T, Cheng T, et al. A survey on latent reasoning[J]. arXiv preprint arXiv:2507.06203, 2025.
- [5] Hao S, Sukhbaatar S, Su D J, et al. Training large language models to reason in a continuous latent space[J]. arXiv preprint arXiv:2412.06769, 2024.
- [6] Hu E J, Shen Y, Wallis P, et al. LoRA: Low‑rank adaptation of large language models[J]. ICLR, 2022, 1(2): 3.
- [7] Wang X, Wei J, Schuurmans D, et al. Self‑consistency improves chain of thought reasoning in language models[J]. arXiv preprint arXiv:2203.11171, 2022.
- [8] Li Z, et al. Compressing Chain‑of‑Thought in LLMs via Step Entropy[J]. arXiv preprint arXiv:2508.03346, 2025.
- [9] Shrivastava V, et al. Sample More to Think Less: Group Filtered Policy Optimization for Concise Reasoning[J]. arXiv preprint arXiv:2508.09726, 2025.
