第 5 名解决方案:多阶段基于热力图的建模
非常感谢竞赛主办方和 Kaggle 举办了另一场引人入胜的挑战——并向所有参与者表示祝贺!
一如既往,我在整个竞赛过程中学到了很多,非常开心。对我来说,这确实是一场直到最后一刻都充满各种情绪的疯狂冲刺。我很高兴在这里分享我的一些解题思路。
更新日志:
- 2025/02/06: 更新了 部分消融实验
整体流程

基于热力图的关键点估计
训练了一个 2D UNet 模型来预测 57 个“特征丰富”的关键点和 43*55=2365 个网格关键点,如下图所示。

我通过检查 ecg-image-kit 源代码获得了所有 2,422 个关键点的确切坐标。“主要”关键点是启发式选择的,通常位于校准脉冲、分割刻度线和导联名称周围,我认为这些地方具有丰富的局部特征。
注意: 我忽略了一些靠近边界的网格关键点,因为它们可能会混淆模型。然而,这在随后的配准阶段造成了很多麻烦。也许保留所有
44*57而不仅仅是42*55个关键点会是更好的选择 :D
非常好的初始伪标签
我使用了一个 SOTA 开源密集匹配模型 MINIMA-RoMa 来获得非常准确的初始伪标签关键点。这涉及简单地将 0001 型图像与训练集中的每张图像进行匹配。

请注意,我没有执行匹配后估计单应性矩阵以将参考关键点扭曲到当前图像空间的操作,因为如果场景是非平面的或局部失真严重,这会生成错误的关键点坐标。相反,对于现代密集匹配模型(如 LoFTR, RoMA 等),我们可以在图像的任意坐标处重采样/插值预测的扭曲流,以估计剩余图像上亚像素级别的匹配关键点坐标。
你可以使用这个很棒的演示快速尝试更新的 SOTA 图像匹配方法:https://huggingface.co/spaces/Realcat/image-matching-webui
建模
训练了一个 2D UNet 模型来预测 58 通道的输出热力图:
- 第一个通道: 单个 2D 热力图,编码所有 2,365 个网格关键点的空间位置。对于每个关键点,绘制一个以该关键点为中心的小型未归一化高斯热力图,相对于标准参考图像(0001 型,
1700x2200)的sigma=2 px,并根据当前图像的尺度(相对于参考图像)自适应缩放。 - 最后 57 个通道: 每个通道编码单个“主要/特征丰富”关键点的位置,同样使用
sigma=2px的高斯热力图,设置与上述类似。

增强训练样本的可视化,从左到右:增强图像,第 2-58 个热力图通道的可视化,第一个通道编码网格点,叠加可视化
模型使用多任务损失进行端到端训练。尽管网络可以仅使用 BCE 损失进行训练,但我对第一个通道使用 BCE,对剩余 57 个通道使用通道掩码 JSD(Jensen-Shannon 散度)。57 个通道中的每一个仅编码单个关键点高斯热力图;空间分布有 0 个峰值(当关键点在图像外时)或 1 个峰值(单峰),不同于第一个通道的多个峰值(多峰)分布。因此,与 BCE 相比,基于空间分布的损失(JSD, KLDiv, CE)提供了更好的归纳偏置/正则化。使用 JSD 可以实现更快的收敛,这在我过去完成的几乎每个实验/项目中都得到了证实。
此外,缩放图像尺寸被证明比缩放模型尺寸更好。我们已经知道,在这个特定任务中,模式/上下文对于模型来说并不难预测(我发现 MaxVit,一种混合 CNN-Transformer,并没有比具有更有限感受野的 ConvNeXT-small 表现更好)。因此,局部模式识别就足够了,允许使用纯 CNN 架构,这更容易扩展到更大的图像尺寸。更大的图像尺寸对于获得细粒度热力图和减少亚像素误差至关重要。此外,如果测试图像中的 ROI 比捕获的图像小得多(例如,相机离物体很远),最长边调整大小 + 填充 变换会破坏细节,因此必须优先考虑分辨率。
我测量了一个类似于 AP@0.5-0.95 的关键点指标用于网格关键点,以及 Accuracy@0.5-0.95 用于 57 个主要关键点,以跟踪最佳模型。用于训练 5 折模型的最终配置如下:
3x2048x2048图像尺寸,最长边调整大小 + 填充,使用双三次插值。- 输出热力图步长为 1,形状为
58x2048x2048。 - 模型:
- 编码器:ConvNeXT-small (convnext_small.fb_in22k_ft_in1k_384)
- 解码器:标准 SMP UNet 解码器,包含 4 个块,通道数为
[384, 256, 128, 64]。尝试了其他选项,如基于 PixelShuffle 的解码器,但表现不如基线。 - MLP 分割头:
64 -> 128 -> 58,带有 GELU 和 LayerNorm。
- 热力图高斯 sigma 为 2 像素(已调优)。
- 多任务损失(2 个损失): BCE(第 1 通道)+ JSD(第 2-58 通道)。
- 多任务加权: GLS (几何损失策略)。GLS 很好——并不总是最好的——但几乎是我在多任务设置中首先尝试的 :D
- 重度数据增强: Affine, Perspective, RandomCrop, GrayScale, RandomBrightnessContrast, ColorJitter, Downscale, Blur, Noise, Dropout (Coarse, Grid, XYMasking),精心设计以保留足够的信息。图像级别的 RandomCrop 和 Dropout 可能有助于解决遮挡/部分裁剪问题,并鼓励更好的全局上下文学习。
- AdamW 优化器,学习率
1e-4,Cosine 调度器。 - 模型 EMA,衰减=0.999。
在热力图模型训练完成后,我使用额外的损失微调了每个折的模型,以在主要关键点预测上实现亚像素精度:对 DSNT 预测和形状为 (57, 2) 的 groundtruth 坐标使用 MSELoss,总共 3 个损失。
迭代伪标签
我在 5 个折上训练了 5 个模型以获得 OOF 预测,解码,然后应用后续部分 关键点配准 中定义的一些后处理逻辑。这个过程被视为去噪过程,我希望模型能学习平均/正确的真值,并跳过 MINIMA-RoMa 初始伪标签中的少量噪声。经过 1 轮后,预测已经足够好,这轮 1 的伪标签被用于训练最终提交的关键点估计模型。
关键点配准
从上一阶段获得热力图后,下一个任务是将热力图解码为离散关键点并正确注册/排序它们。按顺序应用以下逻辑:
- 解码 57 个主要关键点: 简单地对第 2-58 个输出通道的 2D 空间热力图进行
argmax。这样,我们已经知道了正确的关键点顺序。我们可以使用置信度分数来确定关键点是否在图像区域之外,但这不可靠,因为模型没有对“区域外”关键点进行监督(在 JSD 损失中通道被掩码)。幸运的是,后续阶段足够健壮,可以处理错误的区域外关键点预测。 - 对于 5 折模型,我们得到了
(5, 57, 2)解码后的主要关键点。简单地展平为(285, 2),使用这些“几乎重复”的关键点来估计从标准参考图像(0001 型)到当前图像的单应性变换矩阵 H(强假设它是仿射变换)和相对尺度。RANSAC 对异常值具有鲁棒性,因此上一阶段的错误预测/噪声被过滤掉了。 - NMS 阈值(L2 距离)在参考图像中设置为 20 像素,使用上述估计的相对尺度自适应缩放以适用于当前图像 -> 将第一个通道“网格”热力图解码为网格关键点列表(可变长度)。
- 现在剩下的唯一任务是将预测的网格关键点列表与 2365 个参考网格关键点进行 1:1 映射。乍一看似乎很容易,但在现实生活中(以及可能在私有测试集中)会发生许多边缘情况。开发了一种多阶段匹配算法,解决了训练集中提供的所有情况,尽管我相当肯定它并不完美。完全描述会很长,但以下是一些背后的关键思想:
- 使用上一步估计的单应性变换矩阵 H,我们在当前坐标空间和参考坐标空间之间有了双射。
- 使用成对 L2 距离作为成本矩阵的线性分配匹配(匈牙利算法),通过适当的门控成本禁用“不可能”的匹配。
- 使用严格的阈值,例如允许 8 像素误差。这防止了预测的关键点被错误匹配到参考关键点的假阳性匹配。如果纸张不是平面的而是弯曲/皱褶/起皱的,那么 H 不再准确,因此只有一小部分预测的关键点会被匹配。
- 基于高置信度匹配的关键点,使用仅为每个关键点计算的局部单应性矩阵(仅从附近的匹配点估计)重新计算/插值附近的参考关键点。
- 这在一个循环中发生,直到找不到新的匹配点,迭代地匹配所有预测的关键点并将它们注册为正确的索引。漏检将被使用仅来自附近预测关键点的信息的准确插值版本替换,部分解决了“局部失真”问题。
- 最后,对于每张图像,我们获得了一个包含 2,422 个关键点的准确列表(2365 个网格关键点 + 57 个主要关键点)。
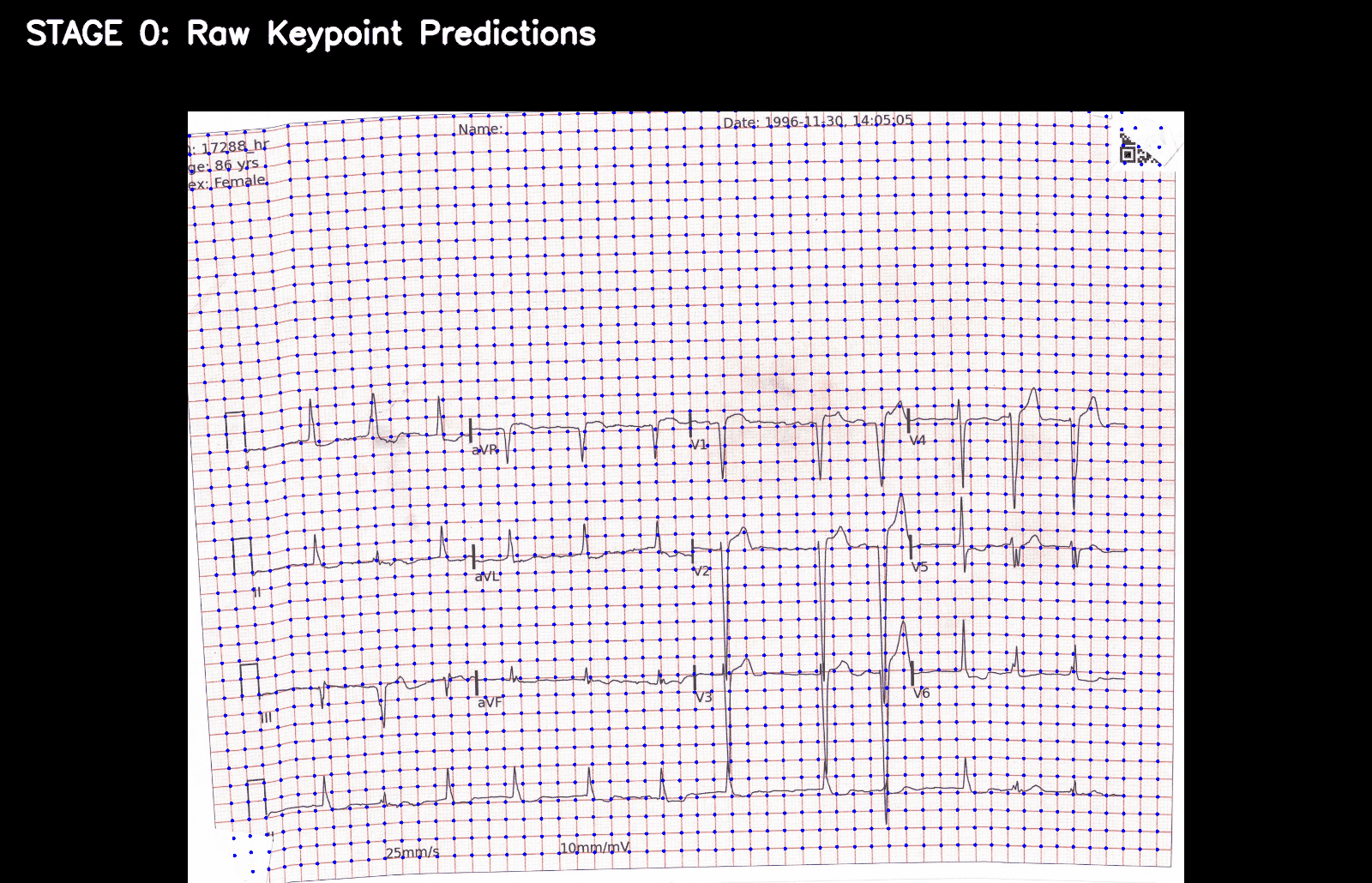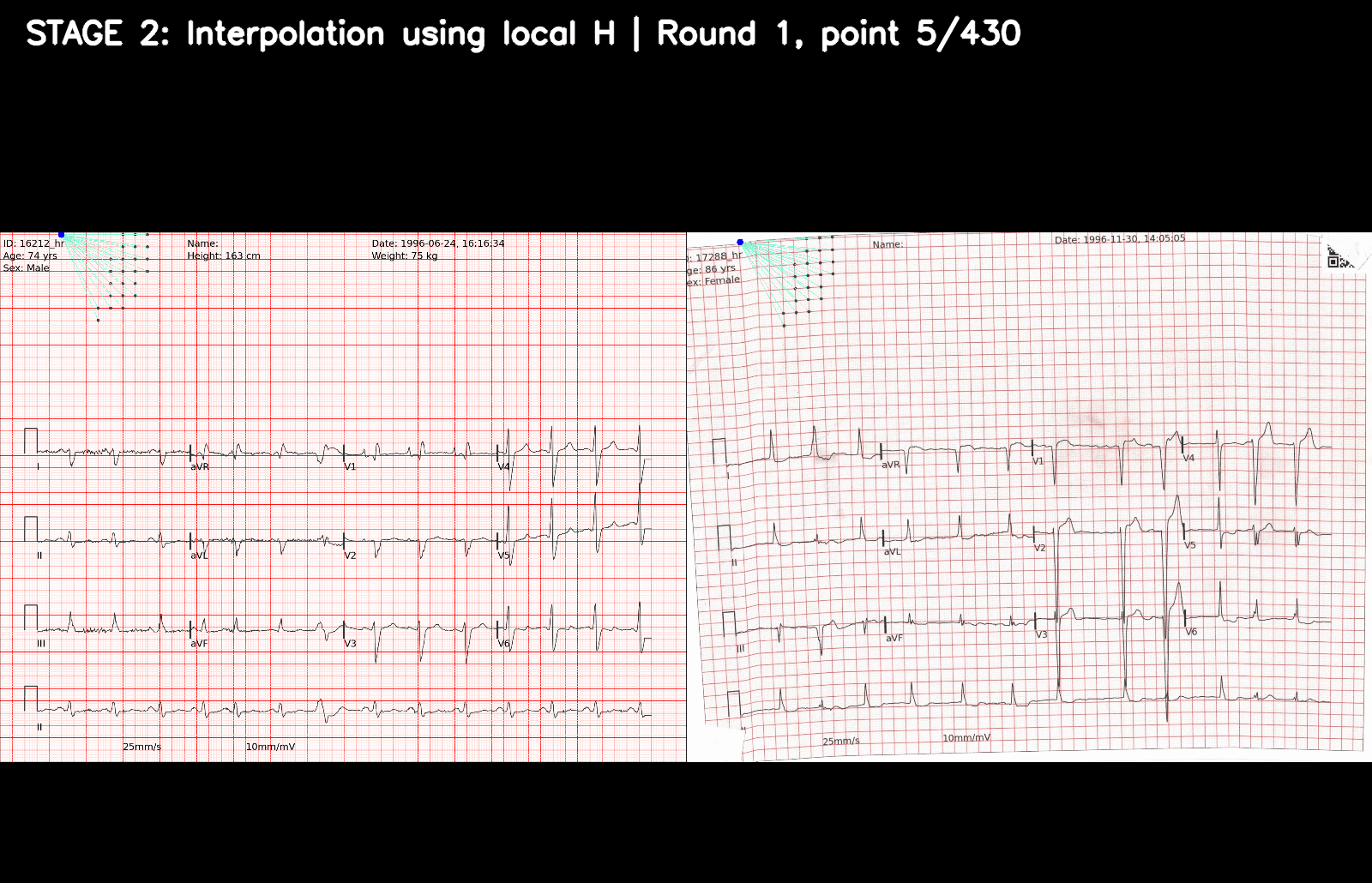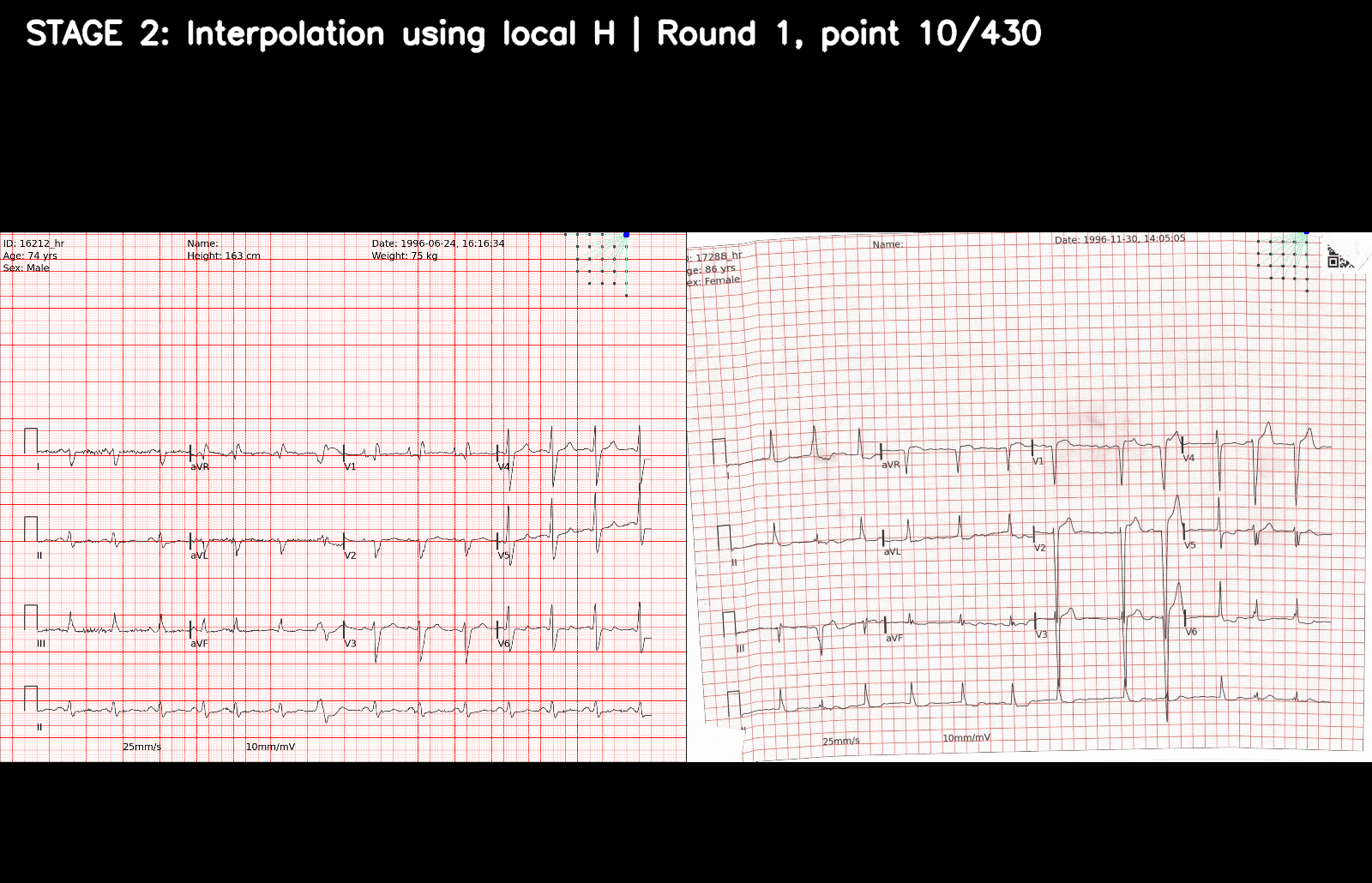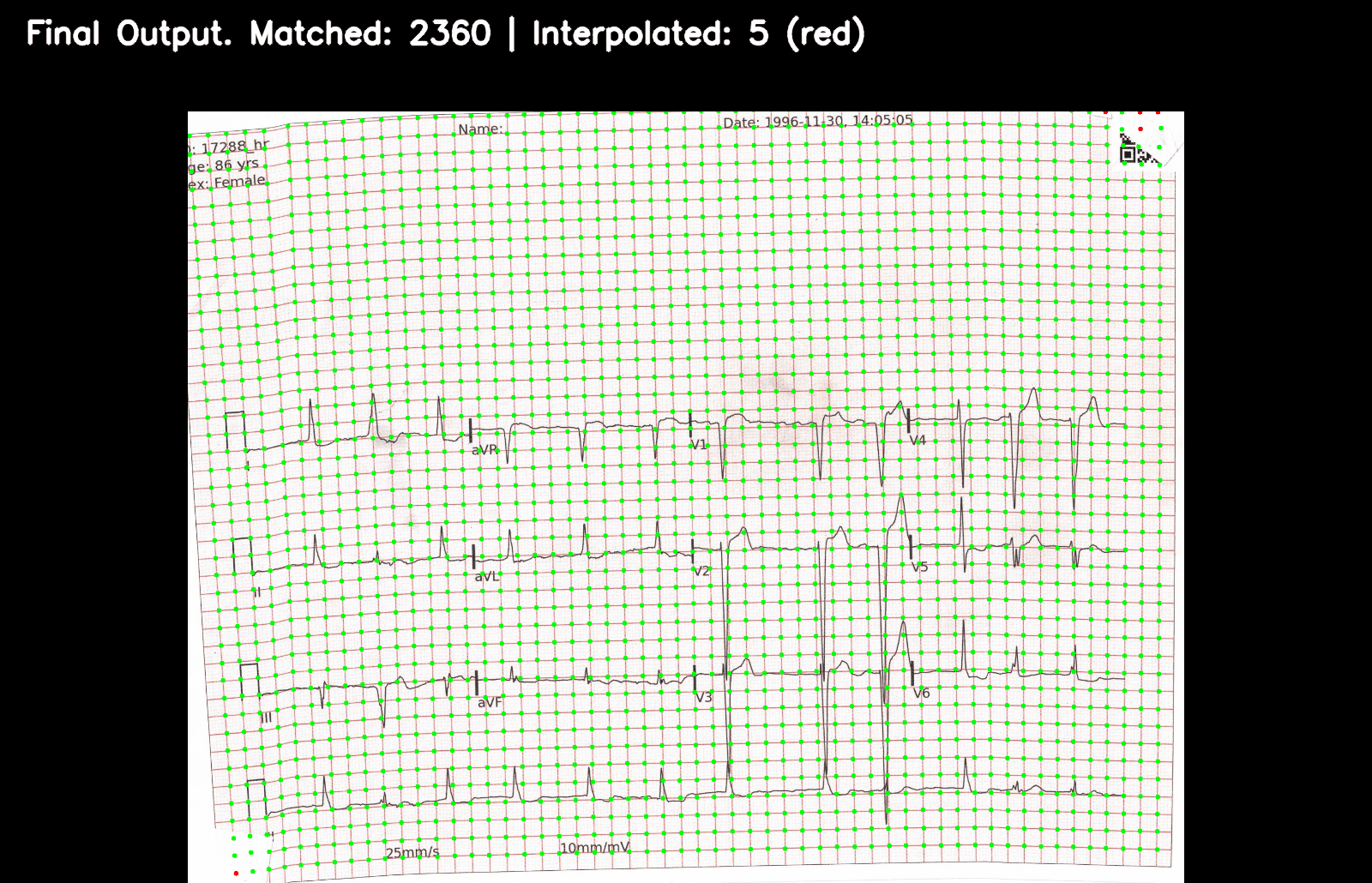
这个 GIF 逐步描述关键点注册算法是如何工作的
导联裁剪
给定原始图像和从前一阶段估计的 2,422 个关键点,我们可以进行裁剪。所有图像都使用相同的参考模板(0001 型),因此更容易使用参考模板中预定义的坐标裁剪出任意感兴趣区域。测试了几种裁剪方法:
- 使用附近的“主要”关键点估计一个单应性矩阵,将当前图像映射到参考图像。
- 估计分段单应性矩阵,将每个单元格(由 4 个网格角定义)从当前图像映射到参考图像,局部使用
cv.getPerspectiveTransform-> 计算流图 -> 使用cv2.remap(或F.grid_sample或scipy.ndimage.map_coordinates)重采样。 - 与 (2) 想法相同,但使用
scipy.interpolate.RectBivariateSpline。 - 与 (2) 相同,但对于每个单元格,使用
cv2.findHomography在K=16个附近关键点上找到局部单应性,而不是像 (2) 中那样仅使用K=4。

方法 (4) 表现最好,因为它不像 (1) 那样过于全局,但保持了足够的“局部性”属性以很好地处理局部失真,同时不像 (2) 那样过于严格局部且对网格关键点估计误差敏感。

使用方法 (1) 由于局部失真导致的错位 - 参见尖峰,但使用方法 (4) 获得了更好的结果
基于热力图的导联波形估计
给定每个导联的扭曲裁剪,训练了另一个 UNet 来预测导联波形的 2D 热力图。 我认为这里的编码方案(编解码器)很重要。对于每个导联,我裁剪出的导联图像区域在左右两侧都稍宽一些,以防止前一阶段的轻微校正错误破坏预测所需的信号。也就是说,即使裁剪向左或向右偏移了几个像素,渲染的波形仍然完全包含在图像中,因此可以被一个好的模型恢复。

至于热力图,我以列独立的方式渲染它。每一列都是一个未归一化的 1D 高斯热力图,在 groundtruth 值处有 1 个峰值 (mu),std (sigma) 值是固定的或根据波形本身自适应改变。因此,每一列始终代表具有单个峰值的概率分布。这种编解码方案是“近乎无损”的,即在编码和解码回(从概率密度函数重新计算期望)操作期间保持了非常高的 SNR。
建模

具有双编码器的 UNet 架构。VGG19 在步长 1/2/4 处编码细粒度特征,而另一个粗编码器(CoaT Lite Medium 或 ConvNeXT Large)聚合全局/附近信息,更好地处理遮挡或捕获长程依赖
事实上,我在截止日期前刚刚训练了这个最终架构一次,以获得一个单一的 checkpoint 进行提交。超参数是基于启发式方法和之前的实验选择的,我将所有“应该有效”的东西组合到了最终的试验中。所有之前的实验都没有引入 VGG19 细粒度/高分辨率编码器,而是依赖于更简单的基线:
- 图像尺寸
512x512,GT 波形重采样为固定长度 500,GT 热力图形状为(1, 512, 512),其中中心区域(1, 512, 500)实际编码 GT 波形。 - 使用方法 (2) 校正,分段透视变换 (
K=4)。 - 具有 ConvNext-small 编码器的 UNet 模型,标准 SMP UNet 解码器输出步长 1的热力图,形状
(1, 512, 512)。 - 列-wise JSD 损失(即在形状为
NCHW的预测张量上使用F.softmax(dim=2))。
一些关键见解:
扭曲插值模式对于防止丢失非常细粒度的细节很重要:
cv2.INTER_LANCZOS4表现最好,并在几乎所有实验中使用。热力图高斯 sigma 相对于参考模板图像 0001 为 2px。
自适应 sigma 缩放:其背后的理由是波形的某些部分比其他部分更难预测,例如幅度在短时间内显著变化的尖峰,导致平行于 mV 轴的“近直线”。应用了一种简单的方法,为局部标准差大的波形值增加 sigma 值。其有效性通过局部 CV 的改进得到了验证。
SIGMA, ADAPTIVE_FACTOR = 2, 0.4 local_abs_diff = 0.5 * (np.abs(arr - np.r_[arr[0], arr[:-1]]) + np.abs(arr - np.r_[arr[1:], arr[-1]])) # 3-sigma 规则:如果 > 3*sigma,开始使用 scale >= 1 adaptive_sigma_arr = SIGMA + ADAPTIVE_FACTOR * np.maximum(local_abs_diff - 3 * SIGMA, 0) / 3
使用了列-wise JSD 损失。简而言之:
JSD>CE>>BCE。UNet 解码器:最终模型使用 6 个 UNet 解码器块,解码器通道
[256,192,160,128,96,64]对应步长64 -> 1,带有 LayerNorm 和 GELU 激活。性能随参数数量增加而扩展。高分辨率特征图中需要更多的通道来保留细粒度纹理细节,但这也会大幅增加内存。对于上采样类型,尝试了基于 PixelShuffle 的解码器,但表现不如传统的 F.interpolate()。还尝试了可变形卷积(v2 或 v4)作为传统 nn.Conv2d 的即插即用替代品,并显示出更好的性能,但由于运行时较慢而未使用;我认为增益来自增加的参数计数。分辨率很重要:使用1024 的输入图像尺寸对于保留纹理细节至关重要,比 512 带来了显著的增益。在此之前,我测试了增益是来自更高的输入分辨率还是更高的输出分辨率,通过扫描一些建模配置:
- 图像尺寸 512,输出热力图尺寸 1024(步长 0.5,带有额外的 x2 上采样 UNet 解码器块)
- 图像尺寸 512,将编码器步长从 4 改为 1 或 2(修改第一个 stem 卷积步长)
- 图像尺寸 1024,输出热力图尺寸 512
- (好得多)图像尺寸 1024,输出热力图尺寸 1024
主编码器:使用了 CoAT 和 ConvNext-large。这两种架构显示出不同的特征。CoAT 在噪声和遮挡图像类型上往往稍好,可能是由于更大的感受野和更输入动态的性质,因此它可以使用附近的信息来猜测遮挡下的内容。同时,ConvNext 更擅长局部性和提取细粒度特征,因此在手机照片等良好和高分辨率图像上具有更好的 SNR。

由于图像尺寸不同(1024 vs 512),比较不公平,但仍显示了每种架构的一些特征:纯 CNN 与混合 CNN-Transformer。
“精细”编码器:VGG19 编码器用于提取步长 1/2/4 的特征图。我们知道这个任务强烈受益于低级特征图和高分辨率,而 VGG 是少数几个默认输出步长 1 特征图的架构之一。VGG 也在 RoMA 中使用,并被证明在提取细粒度局部特征方面优于 ResNet 类架构。我使用了 vgg19.tv_in1k,它不使用 BatchNorm,灵感来自图像超分辨率文献 (EDSR)
空白模板:我使用 ecg-image-kit 渲染一个没有任何导联波形的空图像,作为仅有网格、校准脉冲、分隔刻度线和导联名称的空白模板。每个导联裁剪与相应的灰度空白模板连接, resulting in a 4-channel image to be passed to the 2D UNet model, instead of the original 3-channel RGB image. 我假设模板有助于模型更好地学习校正图像和标准网格模板(与 groundtruth 热力图完美对齐)之间的局部相关性,允许它在内部学习相应地对齐。它还降低了学习特定导联网格布局的复杂性,从而更快收敛

增强:关键的增强是在导联裁剪过程之前(使用局部分段单应性变换 (2))向检测到的网格关键点添加少量噪声(遵循
sigma=0.4px的截断正态分布)。这模仿了现实生活中的错误,因为关键点检测器的预测并不完全准确。我发现通常的增强如 ColorJitter, BrightnessContrast, Grayscale 或非常小的 Affine/Perspective 变换没有太多增益,所以我将这些增强概率设置为较小的值 p=0.1训练:AdamW 优化器,Cosine LR 调度器,按范数 1.0 进行梯度裁剪,模型训练约 70K 步,有效批量大小为 8(批量大小 2,梯度累积 4)
模型 EMA,衰减=0.999
消融实验
详情见 训练代码仓库
图像方向校正
训练集中有 69 张旋转的图像。不确定测试集中有多少,错误的方向会影响关键点检测阶段。所以我训练了一个简单的模型来校正/标准化图像方向。
对于每张图像,我们可以使用单应性 H 获得相对于标准参考图像的确切旋转角度。我简单地训练了一个 efficientvit_b2.r224_in1k 来联合预测 4 种可能的旋转 0/90/180/270 度(分类任务)和由正弦/余弦编码的确切旋转角度(回归任务)。在训练期间,应用了重度增强以确保训练的模型在未见过的私有测试集上具有鲁棒性。当然,训练任务太简单了,所以验证准确率是 100%,角度 MAE 仅在 1.1 度左右。
最终提交
我在截止日期前编写了推理代码并提交;最后一天的一切都是一团糟且糟糕.. 所有提交都包括单个图像旋转/方向模型和 5 折关键点检测模型的推理流程。
前 4 次提交都使用单个模型估计导联波形,没有集成,并且由于热力图编解码器的性质,预测动态也限制在 [-3.2, 3.2] 范围内。有趣的是,仅仅缩放图像尺寸并不起作用——我的模型不能很好地泛化到新的输入尺寸。也就是说,在输入尺寸 [512, 512](可以编码 [-3.2, 3.2] 波形)上训练,然后在输入尺寸 [1024, 512](可以编码 [-6.4, 6.4] 波形)上推理,导致 SNR 非常差。
提交了 4 个单模型:
- (1) 双编码器 CoaT Lite Medium + VGG19,图像尺寸
[1024, 1024],输出热力图尺寸[1024, 1024](第一次训练,无验证)。 - (2) 双编码器 ConvNeXT Large + VGG19,图像尺寸
[1024, 1024],输出热力图尺寸[1024, 1024](第一次训练,无验证)。 - (3) 单编码器 CoaT Lite Medium,图像尺寸
[512, 512],输出热力图尺寸[512, 512](已知最佳学习率)。 - (4) 单编码器 ConvNeXT small,图像尺寸
[1024, 1024],输出热力图尺寸[1024, 1024](已知最佳学习率)。
最终提交:
- 集成 (1) 和 (2),权重分别为 0.7-0.3。
- 导联 II 前 2.5 秒的四分之一融合,权重 0.5-0.5。
- 幸运的是,一个单一的"TALL"模型(单编码器 ConvNeXT-small)接受
[1024, 512]的输入尺寸并能够处理[-6.4, 6.4]范围内的波形,及时训练完成,但得分相对较低(单验证折SNR~21.7),由于调优和训练步骤有限。但这已经足够了,并被用来解决主模型范围有限的问题,作为精炼阶段,当第一阶段的预测接近限制时,例如np.abs(prediction_signal)接近 3.2。 - 它成功地在 LB 上得分 22.93,在 PB 上得分 22.63,在竞赛截止日期前 8 分钟完成——这太疯狂了..
| 模型 | 训练集 SNR | Public LB | Private LB | |
|---|---|---|---|---|
| 双编码器 CoaT Lite Medium + VGG19, 图像尺寸 1024, 热力图尺寸 1024 | 28.006985 | 22.63859 | 22.34824 | |
| 双编码器 ConvNeXT Large + VGG19, 图像尺寸 1024, 热力图尺寸 1024 | 27.484089 | 22.43810 | 22.15886 | |
| 单编码器 CoaT Lite Medium, 图像尺寸 512, 热力图尺寸 512 | 26.050978 | 21.93992 | 21.80577 | |
| 单编码器 ConvNeXT small, 图像尺寸 1024, 热力图尺寸 1024 | 26.081009 | 22.04173 | 21.78336 | |
| 集成 (1) 和 (2) 权重 0.7-0.3, 导联融合, 使用 TALL 模型 1024x512 精炼 | N/A | 22.93061 | 22.62929 |
源代码
训练代码 https://github.com/dangnh0611/kaggle_ecg_digitization 推理 Notebook https://www.kaggle.com/code/dangnh0611/5th-place-solution 处理后的数据集 包含 groundtruth 关键点坐标、空白模板等 Checkpoints & Configs 数据集 最终提交中使用的 checkpoints 和 configs training_logs - Google Drive 所有模型的参考训练日志感谢您的关注!