第三名解决方案 - Matcha与目标检测
首先,祝贺所有参赛者,特别是那些坚持到最后的选手。这是一个非常有趣的挑战,我们很享受解决这个问题的过程。任何在公开榜单达到0.86+分数的人都有可能获胜,所以我们很高兴只下降了2个名次。
感谢@crodoc的出色团队合作,我们对如何解决问题有两种不同的观点:他采用端到端的方法,而我希望进行目标检测和OCR。事实证明,这对本次竞赛而言是理想的方案,因为目标检测弥补了端到端方法的弱点。
概述
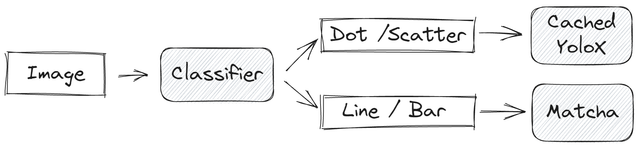
我们的解决方案是一个两步流程,第一步是简单的分类任务,第二步针对不同的图表类型解决问题。对于散点图和点图,我们使用检测方法。对于折线图和条形图,Matcha表现非常出色。以下是我们的榜单分数:
| 总体 | 散点图 | 点图 | 折线图 | 水平条形图 | 垂直条形图 | |
|---|---|---|---|---|---|---|
| 公开榜 | 0.87 | 0.09 | 0 | 0.33 | 0.04 | 0.39 |
| 私有榜 | 0.71 | 0.28 | 0.01 | 0.13 | 0.01 | 0.27 |
验证与洞察
根据描述页面:
训练集和公开测试集中提取的图形来自相同的来源集。私有测试集中的图形来自不同的来源集。
公开榜存在数据泄露,我们需要创建能够泛化到新数据来源的模型。因此,我们将所有提取的数据用作验证,仅对生成数据进行训练。主办方提供的数据多样性不足以实现泛化,所以我们自己生成了数据。Matcha和分类模型在经过仔细的参数优化后,对所有数据进行了完整训练,但检测模型没有在任何提取数据上进行训练。
对于点图的验证,我们使用了一个在Google图片上找到的20张图像组成的小型精选数据集。我们通过探测估计测试集中有100到125个点图,其中所有点图很可能都在私有测试集中。不过我们没有对散点图进行探测,这本来会很有帮助。
步骤1 - 分类
这里没有什么特别之处,我们在(benetech + theo + crodoc)生成的数据上训练了模型。
主要参参数:
- 88k张图像上训练2个epoch
- 学习率
3e-4或5e-4(混合使用2个学习率,我们还使用了2个种子) - 主要是Mixup和一些颜色增强
- 256x384图像尺寸
- 使用0.2 dropout的NfNet-l2
步骤2.a - 散点图
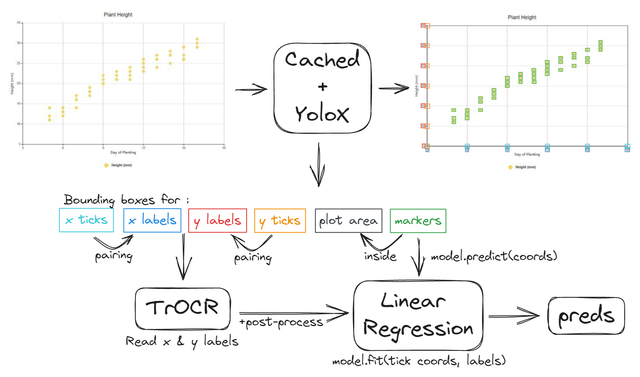
对于散点图,我们依赖YoloX来检测所有标记。Cached用于处理其他有用元素。如果所有点都被正确检测,推断目标就不复杂:检测刻度线和标签,读取标签,然后进行插值!
更多细节:
- 集成YoloX-m和YoloX-l模型并使用NMS,有助于减少漏检
- 模型在散点图+点图的benetech生成数据以及我生成并伪标记的大量图表上训练10个epoch
- CV 0.67,公开榜0.09~,私有榜0.29 - 性能下降几乎完全来自重叠/难以检测的标记
- 大量后处理使管道对OCR错误和检测错误更加鲁棒
- 我们最初使用Yolo-v7,但由于第一次规则变更不得不切换到YoloX。我们花了一周时间才使YoloX的性能与Yolo-v7相匹配
步骤2.b - 点图
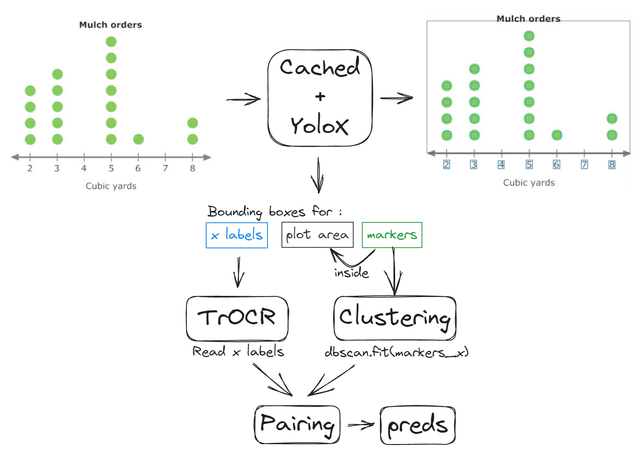
点图管道与散点图类似,但更简单一些。我们检测点并对其进行聚类,然后将其映射到检测到的x标签。没有分配聚类的标签目标值为0,其他标签的目标值为检测到的点的数量。计数点对检测错误不是很鲁棒,因此我们改为使用最上方点的高度并进行插值。
步骤2.c - 条形图和折线图
Matcha在这里表现非常强大。我们使用matcha-base并设置is_vqa=False以避免将文本作为输入提供给模型。
我们训练Matcha来预测图像的图表类型、xs和ys。ground truth看起来与@nbroad用于donut方法的方案相同(除了我们删除了prompt token)。我们尝试了其他方法,但这个效果最好:
x_str = X_START + ";".join(list(map(str, xs))) + X_END
y_str = Y_START + ";".join(list(map(str, ys))) + Y_END
ground_truth = '<' + chart_type + '>' + x_str + y_str例如:<line><x_start>0;2;4;6<x_end><y_start>2.7;2.2;3.6;5.2;<y_end>
通过matplotlib生成额外图表为我们带来了最有价值的提升。我们重用训练数据集中的值和文本生成刻度和值,使用不同的样式/图案/字体/颜色来增加多样性。生成额外图像的代码大约有1000行,基本上涵盖了模型在"提取"数据集上验证失败的大多数情况(例如负值、线边缘、缺失条形、多行文本、文本旋转)。
其他有帮助的改进:
- 根据数值范围固定小数位数:
number_of_decimals = max(0, round(np.log10(1/ (max(y_ticks) - min(y_ticks))) + 3) - 我们使用额外的图表类型:直方图,让模型学习到这类图表少一个y值
- 为图表类型添加额外的交叉熵损失
- 集成多个(4个)模型(+0.01公开榜):
- 投票计算输出数量并修正明显错误
- 分类预测的投票
- 连续预测的平均
更多细节:
- 学习率3e-5,带0.25周期的余弦退火
- 10个epoch
- 每0.25个epoch保存权重,并使用epoch>1的所有检查点进行模型融合
- 增强:颜色变换、图像压缩和随机缩放
结语
我们受到了意外的第二次规则变更的极大干扰,特别是考虑到我当时正在度假。在最后3天里,Matcha和分类模型在ICDAR上进行了重新训练,这使公开榜提升了0.01,但在私有榜上没有任何改进。
感谢阅读!