第 8 名解决方案
从关键点到热力图再到信号:三流程集成
概述
我们最好的提交作品通过运行三个独立的解决方案,然后计算它们预测值的加权平均来实现。我们在比赛后期组建了团队,因此我们的流程是在相对较少的共享假设下开发的。这种独立性增加了模型的多样性,从而使我们的集成模型能够显著超越 individual 分数。
| 解决方案 | 集成权重 | 公共 LB 分数 | 私有 LB 分数 |
|---|---|---|---|
| Imanishi 的流程 | 45% | 21.58 | 21.43 |
| James 的流程 | 32% | 21.17 | 20.98 |
| Liu 的流程 | 23% | 20.84 | 20.74 |
| 集成模型 | N/A | 22.16 | 22.03 |
总的来说,我们所有的解决方案都是通过校正输入图像以纠正失真,然后使用分割模型和 softmax 操作来提取电压信号。然而,我们在预处理方法(1 阶段 vs 2 阶段)、模型架构(CNN vs Transformers)、分割损失函数(二元交叉熵 vs 自定义"coord"损失)以及信号后处理方法(异常抑制技术和信号锐化变换)方面存在一些实质性差异。因此,我们预测中的不准确之处 largely 不相关,加权平均大大提高了信噪比。
我们的 individual 解决方案将在下面详细描述。
Imanishi 的流程
Imanishi 部分概述
使用 hengck23 优秀的 notebook 作为基线,我引入了以下改进:
- 用我自己训练的模型替换了 stage0 模型。最初的动机是在计算 CV 分数时完全排除预训练数据,但由于它也提高了 LB 分数,所以我采用了它。(Stage1 最终保留了 hengck23 的模型。)
- 当为 stage2 转换为校正输入图像时,hengck23 分两步执行变换。为了减少图像质量下降,我改为从 stage0 和 stage1 的输出计算网格,并使用
F.grid_sample()单步变换原始图像。 - 增加了 stage2 输入分辨率,特别是在 x 方向(输入大小:1632 × 4480)。
- 将队友 liuzhangzhen 的 Coord loss 想法引入 stage2。
- 在 stage2 中添加了基于 y 方向聚类的掩蔽。
- 我没有用 0 mV 填充 stage2 中的低置信度预测,而是 switched 到 线性插值。
- 为 stage0 和 stage2 模型采用了 EfficientNetV2B1-UNet(尚不清楚这对准确性有多大贡献)。
- 添加了以下后处理:
- 使用 爱因托芬定律 (Einthoven's law) 校正导联 I、II 和 III。
- 由于 Lead II 的前四分之一与两个波形重叠,应用平均集成。
- 应用
savgol_filter,根据sig_len动态调整window_length。
Stage2 模型详情
在 Liu 的 Coord loss 实现中,分割损失和 Coord loss 都应用于相同的 logits。在我的情况下,这效果不好,所以我 model head 分成两个 heads(分割 head,y 坐标 head),并分别应用 分割损失 (dice loss + BCE loss) 和 Coord loss。
两个 heads 具有相同的输出形状:[height, width, 4ch]。
分割损失在训练期间充当辅助损失,但分割输出也用于推理期间掩蔽 x 方向的低置信度区域以及稍后描述的 y 聚类。
Coord Loss
虽然 Liu 的部分已经解释了 Coord Loss,但我会描述我认为重要的部分。
使用像 hengck23 基线那样的基于分割的方法,其中预测曲线掩码然后使用 argmax 获取 y 坐标,很难估计最佳 y 位置。查看两个 heads 的 ground truth 时这一点变得很明显(下图)。
使用 Coord Loss,logits 输出(height × width × 4 通道)与分割 head 相同,直到某一点,但随后在 y 维度上应用 softmax 以直接预测 y 坐标。
如果我们使用只有一个像素的 one-hot 标签作为 ground truth,模型会对小坐标偏移非常敏感。相反,ground truth 沿 y 轴表示为 高斯形状的概率分布。高斯参数(sigma 和 radius)与 Liu 的保持一致,因为我没有时间调整它们。
损失函数是标准的 交叉熵损失,将问题视为 y 位置上的多类分类。
通过在 Coord Loss head 输出上沿 y 方向应用 argmax,我们可以获得更准确的 y 坐标。添加 Coord Loss 使我的公共 LB 分数提高了约 +1.0 dB,这是一个巨大的增益。
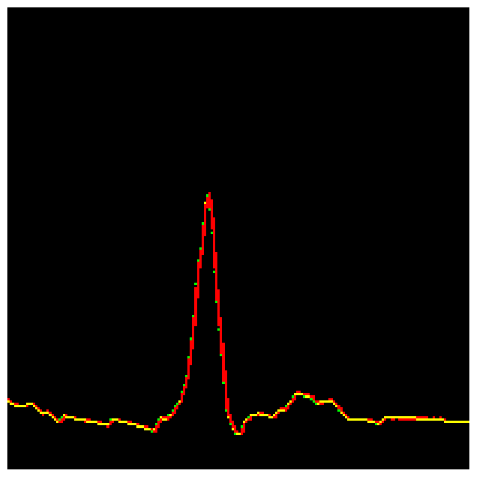
Y-聚类
出于某种原因,我的 stage2 模型偶尔会错误分类导联标签,这可能会显著降低 SNR。我想在训练期间防止这种情况,但最终未能做到,所以我用 使用 y 方向聚类的后处理步骤 来处理它。
对于 y 聚类,我使用了分割 head 的输出,生成的掩码随后应用于 y 坐标 head。

其他技巧
在提交 notebook 中,我将整个测试集分为两部分,并为每个进程分配一个 T4 GPU,如下面的代码所示,以加快推理速度。
实际上,我的这部分流程运行大约需要 70 分钟,这是团队成员中最快的。
env1 = os.environ.copy()
env2 = os.environ.copy()
env1['CUDA_VISIBLE_DEVICES'] = '0'
env2['CUDA_VISIBLE_DEVICES'] = '1'
cmd1 = f'python run.py --half 0'
proc1 = subprocess.Popen(cmd1.split(' '), env=env1)
cmd2 = f'python run.py --half 1'
proc2 = subprocess.Popen(cmd2.split(' '), env=env2)
_ = proc1.communicate()
_ = proc2.communicate()James 的流程
概述
我的推理流程有 3 个主要步骤:
- 预处理: 检测图像中的地标并使用它们校正仿射扭曲(如相机视角变化和旋转,但不包括纸张褶皱)。
- 导联分割: 预测一个热力图,描述如果输入图像完全“干净”且无失真,导联假设位于何处。这比处理由不完美的非仿射扭曲校正引起的不自然失真更好地处理“自然”失真,因此在我的流程中尝试使用类似 @hengck23 基线的预处理逻辑校正非仿射扭曲是有害的。
- 热力图到信号转换: 我使用 top-k softmax 操作预测每个时间步每个导联的估计电压和置信区间,用从上下文插值的预测替换极低置信度的预测,使用顶帽变换“锐化”剩余的电压尖峰,并使用一点线性代数利用导联之间的冗余进行去噪。
步骤 1 和 2 都使用微调版本的 DINOv2-base。我总共使用了 6 个模型的集成,步骤 1 中 2 个,步骤 2 中 4 个。一半的模型以故意翻转的方向处理图像,作为测试时数据增强的一种形式。
数据生成
我基于 PTB-XL 数据集中的约 22K 独特 ECG 记录生成了约 175K 训练示例。
这是通过 ECG-image-kit 生成“干净”的 ECG 图像,然后故意用一些自定义数据增强代码破坏它们,试图大致模仿主机数据中出现的图像类型(严重损坏的纸张手机照片、电脑屏幕手机照片、黑白扫描等)。
每种图像类型大致使用以下组合模拟(顺序不分先后):
- 仿射扭曲
- 背景图像插入: 对于模拟手机照片,扭曲的 ECG 图像叠加在来自 unsplash-25k 的图像顶部。对于扫描照片,我使用白色背景。
- 污渍插入: 这是通过将半透明霉菌和污渍图像叠加在 ECG 图像上来工作的。污渍是从 26 个池子中随机抽取的,我通过提示扩散模型半手动生成。事后看来,我认为我使用的污渍强度分布有点不现实(通常太透明),想知道是否也许 pwelin 噪声比我生成的污渍图像效果更好,但从未来得及推敲第二个版本。
- 褶皱阴影: 这模拟了假设褶皱的阴影,而不引入任何非仿射扭曲。它与 ECG-image-kit 的功能非常相似,我只是让 ChatGPT 将其移植到我的脚本中。
- 黑白扫描器模拟: 这不是现成的灰度转换。我试图通过随机化亮度、对比度、gamma 以及输入颜色通道的加权方式来模拟黑白扫描器的行为。它还注入了一点高斯噪声以模仿传感器噪声和量化伪影。
额外的增强是在我的训练脚本中动态执行的,那些只是我在训练前应用的。
在约 175K 额外训练示例中,只有约 50K 用于训练我的最终模型。主要是因为 (1) 关键点检测器的准确性似乎在约 17K 训练示例后没有 meaningful 提高,(2) 在主机图像上微调之前在合成数据上预训练导联分割模型的增益相对于消耗的 GPU 时间来说相当小(额外计算超过两天 RTX 5090 仅获得 +0.17 dB 增益有点令人失望……我想尝试其他事情,而不是让硬件被困在那个方向上 pushing further)。
相机视角校正
这是通过检测图像中的关键点,然后使用那些关键点位置计算单应性矩阵来工作的,该矩阵可用于校正相机角度、缩放和旋转的差异。它与 @hengck23 的 stage 0 相当相似,主要区别是我使用了视觉 transformer 而不是 CNN,以及我自己生成的训练数据。
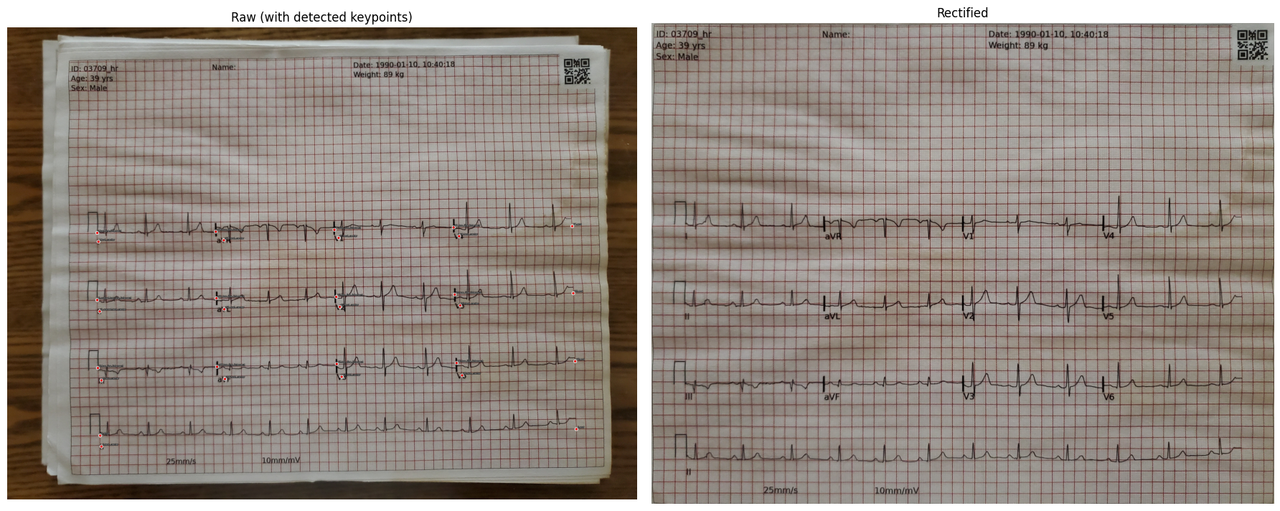
关键点在 1036x1036 分辨率下检测,然后用于直接将图像从其 native 分辨率校正为 --> 1694x2198。
训练详情:
- 模型架构:DINOv2-base 骨干网络,带有线性预测 head,产生 30 通道输出(每个目标地标 1 个,所有导联标签文本 + 每个信号 x 轴的起点和终点)。
- 训练模仿 ground truth 热力图,每个关键点 1 个“高斯 blob"。这些 blobs 中心值为 1,随着距中心距离增加衰减向零。
- BCE 损失
- AdamW 优化器
- 单周期学习率调度
- 数据增强(使用
albumentations应用):RandomRotate90GridDistortionElasticTransformOpticalDistortionGaussNoiseGaussianBlurRandomBrightnessContrastColorJitterCoarseDropout
我最终集成中的两个关键点检测模型都在 17.4K 我的合成训练示例上训练(没有主机数据)。它们主要在数据增强设置和训练 epoch 计数上不同。一个用中等重度增强和 24 epochs 训练,另一个用更重增强和 48 epochs 训练。
将训练数据 triple 到约 50K 示例在针对其他合成图像测试时提高了交叉验证,但在针对主机提供的 ECG 图像测试我的完整流程时没有提高分数,因此只有约 10% 的可用合成数据用于训练我最终集成中的关键点检测器。
导联分割
我使用 ground-truth 信号数据生成“完美”热力图,描述如果图像完全无失真,导联应该位于图像中的何处,然后微调 DINOv2-base 以基于具有 realistic 失真的图像预测那些热力图。这教会它自动校正任何穿过我预处理的扭曲。
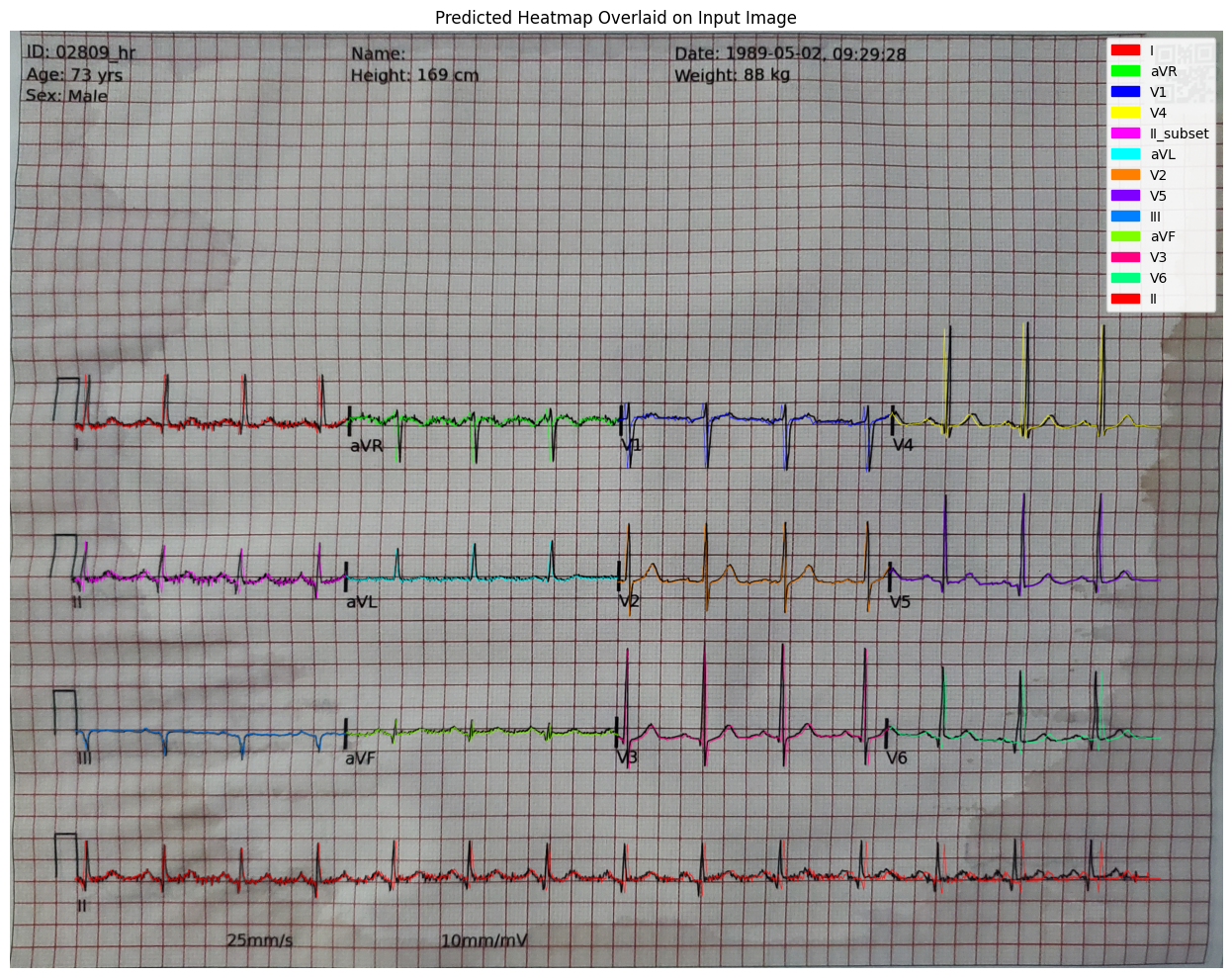
我发现使用高于 ECG plots native 分辨率的水平分辨率非常有益,因此这使用 1694x4396 的输入分辨率(比 native 宽约 2 倍),我在 transformer 骨干网络和预测 head 之间插入了一个 ConvTranspose2d 层,这在产生输出前不久将分辨率又提高了 2 倍。结果,热力图的分辨率为 1694x8792。与仅使用 naive 分辨率相比,这提供了 巨大的分数改进,早期实验中约 4.1 dB 增益。使用比 native 高 2 倍的输入分辨率和比 native 高 4 倍的输出分辨率似乎是最优的,调整其中任何一个数字 2 倍都会使分数变差。
训练分 2 个阶段进行:
- 在我的合成图像上预训练
- 在主机图像上微调
训练详情:
- 数据: 阶段 1 每个模型使用 17.4K 合成图像,集成中的每个模型使用不同的图像。阶段 2 使用 80% 的主机数据,20% 保留用于交叉验证。
- 掩码生成: 与关键点检测模型不同,我发现用于训练这些模型的 ground-truth 分割掩码非常 sharp 是有益的。ground-truth 导联线只有一个像素厚,没有模糊。
- 激活检查点: 在高分辨率下训练视觉 transformer 使用大量内存。我使用 激活检查点 来缓解这个问题。它允许速度和内存使用之间的可配置权衡。我发现速度缺点极小。它可以将内存使用量减半,几乎零减速。
- 数据增强: aggressive 数据增强似乎对这些模型弊大于利,所以我使用相对轻量的配置。对于集成中的大多数模型,我在预训练期间只使用了
A.GridDistortion(num_steps=5, distort_limit=0.2, p=0.15),并且在微调期间没有任何 显式 数据增强。然而,微调故意使用来自我的预处理流程较旧、较不准确版本的校正图像,因此模型在训练期间比测试时暴露于更多校正错误。对训练数据使用更准确的校正使我的分数变差,所以我相信校正不准确在微调期间充当了一种 sneaky 数据增强。 - 损失函数: 我集成中的 4 个导联分割模型中的 3 个仅训练以最小化二元交叉熵损失。其中一个在微调期间使用混合损失,其中它还试图最小化每个时间步预测 y 像素坐标的均方误差。这似乎 略微 有益(交叉验证中 0.05 dB,leaderboard 上更少),但我没有时间将其传播到集成中的所有模型。像那样应用 L1 或 L2 损失是我在比赛早期 consistently 弊大于利的事情,所以我最初放弃了,但在添加预训练后似乎有些有益;我认为在添加 MSE 或 MAE 之前纯粹用 BCE 预训练有助于防止我早期遇到的许多过拟合和不稳定。
- 杂项: AdamW 优化器和单周期学习率调度器,类似于关键点检测器。
测试时增强和集成
我的流程使用单独的关键点检测模型将每个图像校正两次,然后翻转其中一个结果图像,并将它们 fed 到 4 个导联分割模型的集合中,其中一半训练为处理翻转方向的图像。然后将生成的热力图通过平均像素 logits 混合。
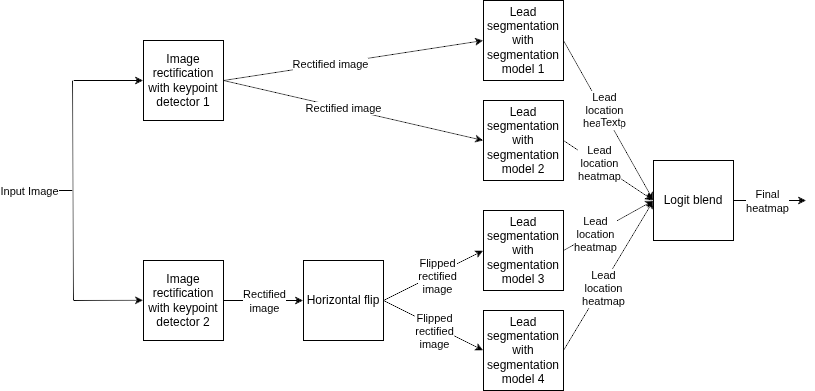
上述方法基于以下观察:
- 平均标准和翻转方向模型的预测提供约 0.28 dB 的增益。
- 每个方向使用 2 个导联分割模型提供约 0.18 dB 的增益。
- 使用 2 个模型进行校正(而不是 1 个)提供约 0.13 dB 的增益。
- 平均像素 logits 得分比信号提取后平均好约 0.02 dB。
- 在校正前翻转或旋转图像没有帮助。
分数可能通过以更多方向处理图像、应用其他顶级解决方案和公共 notebook 中与旋转和翻转无关的一些测试时增强,并找出为什么在校正前应用 TTA 没有帮助(也许我有 bug?)来进一步提高,但我没有时间非常 extensively 实验这个。
信号提取和后处理
我通过以下步骤将原始预测导联位置热力图转换为信号:
- 热力图 --> 原始信号: 在基于规范布局预期导联位于的图像每一列内,我使用 top-k softmax 计算导联位于每个垂直像素坐标的估计概率,然后使用那些概率估计计算预期信号值。使用 k=10 的 top-k softmax 得分比使用 hard argmax 好约 0.28 dB。我尝试了 k ∈ {3, 5, 10, 20, unlimited},发现 5 和 10 大致并列“最佳”。最佳选择因模型而异,取决于其他超参数的细微差异。
- 不自信预测替换: top-k softmax 操作也用于计算每个时间步信号值的上下置信界限。如果那些界限相差超过 0.4 mV,则丢弃样本,并通过从周围上下文样本线性插值填充间隙。置信区间覆盖的范围对应于每个时间步最可能的 10 个垂直像素坐标,或关联概率估计高于 0.1% 的最小和最大像素坐标, whichever 更窄。与没有置信过滤的基线相比,这提供了约 0.13 dB 的增益。
- 边缘伪影抑制: 我通过用位于从右数第 3 个的电压样本替换每个导联最右边的 2 个电压样本来移除边缘伪影。最右边的样本往往不准确,因为"ground truth"训练信号包含一些在打印图像中不可见的电压尖峰,这导致模型倾向于在末端 hallucinating。部分抑制那些错误给了我约 0.05 dB 增益(其中一些泄漏通过这个过滤,2px 安全边际不够宽以完全消除它们)。
- 信号锐化: 由于输入图像分辨率低于它们基于的原始信号,电压尖峰的峰值往往有点“圆润”,因此使用 顶帽变换 来锐化它们。这提供了约 0.04 dB 的增益。它比我用 shock 滤波器锐化(CV 中 +0.01 dB 增益,未在 LB 上测试)或 1D 反锐化掩蔽(CV 中有害,未在 LB 上测试)效果更好。
- I/II/III 冗余利用 (爱因托芬定律): 这分几个阶段发生。首先,对齐 I 和 III 导联与 II 以校正小时间差异。然后使用 II = I + III 关系(爱因托芬定律)基于其他两个计算这 3 个导联中每个的“预期”信号值。最后,原始提取信号与其预期值通过加权平均混合,三分之二权重分配给原始值。这提供约 0.05 dB 的增益。首先对齐信号至关重要,否则这对我有害。我还尝试以类似方式利用 aVR + aVL + aVF = 0 关系,并在本地交叉验证中观察到类似的增益,但与 I/II/III 不同,aV* 后处理在 leaderboard 上效果不佳,所以我的最终流程仅对 I/II/III 进行爱因托芬后处理。
- II 和节奏条冗余利用: II 信号在每个图像中出现两次,一次作为 2.5 秒段,然后再次作为 10 秒段(节奏条),其前缀应与较短段匹配。我的 II 预测通过将较短信号与较长信号对齐(校正小时间差异),然后计算加权平均生成,约 56% 权重给长信号,约 44% 给较短信号。这提供约 0.01 dB 增益……几乎不可测量,但对 CV 和 LB 都是一致的。
- 采样率调整: 信号通过线性插值重新采样以匹配主机所需的采样率。我还尝试了立方、akima 样条和 PCHIP 插值,但线性效果最好。
对我效果不佳的事情
- 在预处理期间校正非仿射图像扭曲
- DeepLabV3 分割模型
- 更大的 DINO v2 模型
- DINO v3
- 使用 1D CNN 后处理
- 使用可微扭曲操作以便预处理模型可以与最终导联分割模型端到端训练
……像往常一样,许多对我效果不佳的事情如果付出额外努力和 GPU 时间进行调整,潜在地可能对其他人效果良好。当早期结果看起来没有希望时,我经常继续测试其他想法。许多上述“坏”想法最终对其他顶级竞争对手效果良好 😅
Liu 的流程
致谢
我要向 Kaggle 和比赛组织者提供这个宝贵机会表示衷心感谢。特别感谢 @hengck23 分享他的强基线,这为我工作 served 了 crucial 基础。
总结
我的解决方案优化了 @hengck23 基线的 Stage 2。关键洞察是将波形提取视为 每列坐标回归,而不是纯粹依赖“分割 → 后处理”流程。
我保留 U-Net 风格的热力图预测以保持稳定性,但添加 CoordLoss:一个 GT 中心的 局部高斯交叉熵,直接监督每列中心线 y 坐标。在我的本地验证 split 上,这一单个改变将 SNR 提高了 超过 +1 dB,它是整体质量的主要贡献者。
为了进一步减少训练 - 推理不匹配,验证/推理使用相同的 旧子像素兼容 y 提取器(NaN + 插值行为)。我还添加轻量级“安全”正则化项强制执行物理上合理的导联关系。
整体流程
Stage 0/1 (基线): 检测并将 ECG sheets 校正为规范坐标(校正条)。
Stage 2 (本工作):
- 模型:ResNet34 编码器 + U-Net 解码器 → 4 个热力图 (3 个短行 + 长 Lead II)。
- 损失:
- 掩码 BCE (热力图监督)
- CoordLoss (主要增益)
- 小辅助损失 (一致性 + 导联关系)
- 推理:
- 预测全宽 logits
- Logits → y(px) 使用与验证相同的旧子像素提取 (NaN → 插值)
- 转换 y(px) → mV
- 对边界附近的长 Lead II 应用基于爱因托芬的修补
Stage 2 模型
架构
- 编码器:
timm resnet34.a3_in1k - 解码器:U-Net 风格解码器 (MyCoordUnetDecoder),带多尺度 skip 连接
- Head: 1×1 conv → 4 个热力图
BatchNorm 冻结
所有 BN 层在训练期间强制进入 eval 模式,这在 batch size 1 带梯度累积下稳定优化。
损失
- 掩码像素 BCE (基线监督)
我将 GT 折线 rasterize 为薄热力图掩码并应用 BCEWithLogitsLoss,由有效列掩码。由于最终指标受节奏条强烈影响,我 upweight 长 Lead II (通过通道加权和/或 multiplicity 取决于运行)。 - CoordLoss (主要增益,+1 dB)
动机:分割风格 BCE 不直接优化我们最终需要的 quantity—每列中心线 y 坐标。即使小垂直错误也会在对齐和插值后降低 SNR。
方法:对于每个通道 c 和有效列 x- 将高度上的 logits 视为分类分布:
p(y|x,c)=softmax(z_c[:,x]/T)
- 在连续 ground-truth
y^*(x,c)周围构建 GT 中心局部高斯目标:w_k ∝ exp(-(k-y^*)^2/(2σ^2))在窗口 ±R 内
- 在该局部窗口内使用 log-softmax 值计算交叉熵 (局部高斯 CE)
- 将高度上的 logits 视为分类分布:
- 辅助“安全”正则化项 (小权重)
- 短 II vs 长 II dy 一致性:仅应用于 segment0 (短 II 时间),使用 SmoothL1 在 centered dy 上以减少 drift/slope 不匹配。
- 爱因托芬桥 (mV 域): 鼓励边界附近的长 II 匹配爱因托芬校正
(II_corr=(1-w)*II+w*(I+III)),带 warmup/ramp 以保持稳定。 - 导联关系惩罚 (hinge): 在 segment0 上使用 tolerance-based squared hinge 强制
II ≈ I + III。
这些 intentionally 轻量级;它们主要帮助避免 implausible 输出并减少边界伪影,而 CoordLoss 提供主要准确性提升。
集成方法
我们通过以下方式集成我们的预测:
- 对齐信号以校正小时间差异,否则如果 naive 平均信号,这些差异将充当 blur 滤波器。这是使用从评估指标复制的代码完成的,非常类似于它如何将信号与 ground truth 对齐。
- 计算预测的加权平均。我们只做了 2 次提交来尝试调整权重,所以它们主要基于 rough guesswork,即假设每个流程预测的最佳权重可能与其公共 LB 分数相关。使用在该方向上 lean 更多的权重比使用相对 even 权重得分更好(在公共和私有 leaderboard 上),所以该假设似乎是正确的。
这比我们最好的 individual 提交提供了 0.6 dB 的增益 😁。