祝贺所有获奖牌的竞赛选手🎉🎉。这是一个学习和成长的好机会。我想在此分享我的方法。
我的解决方案包含两个主要步骤:目标检测和光学字符识别(OCR)。
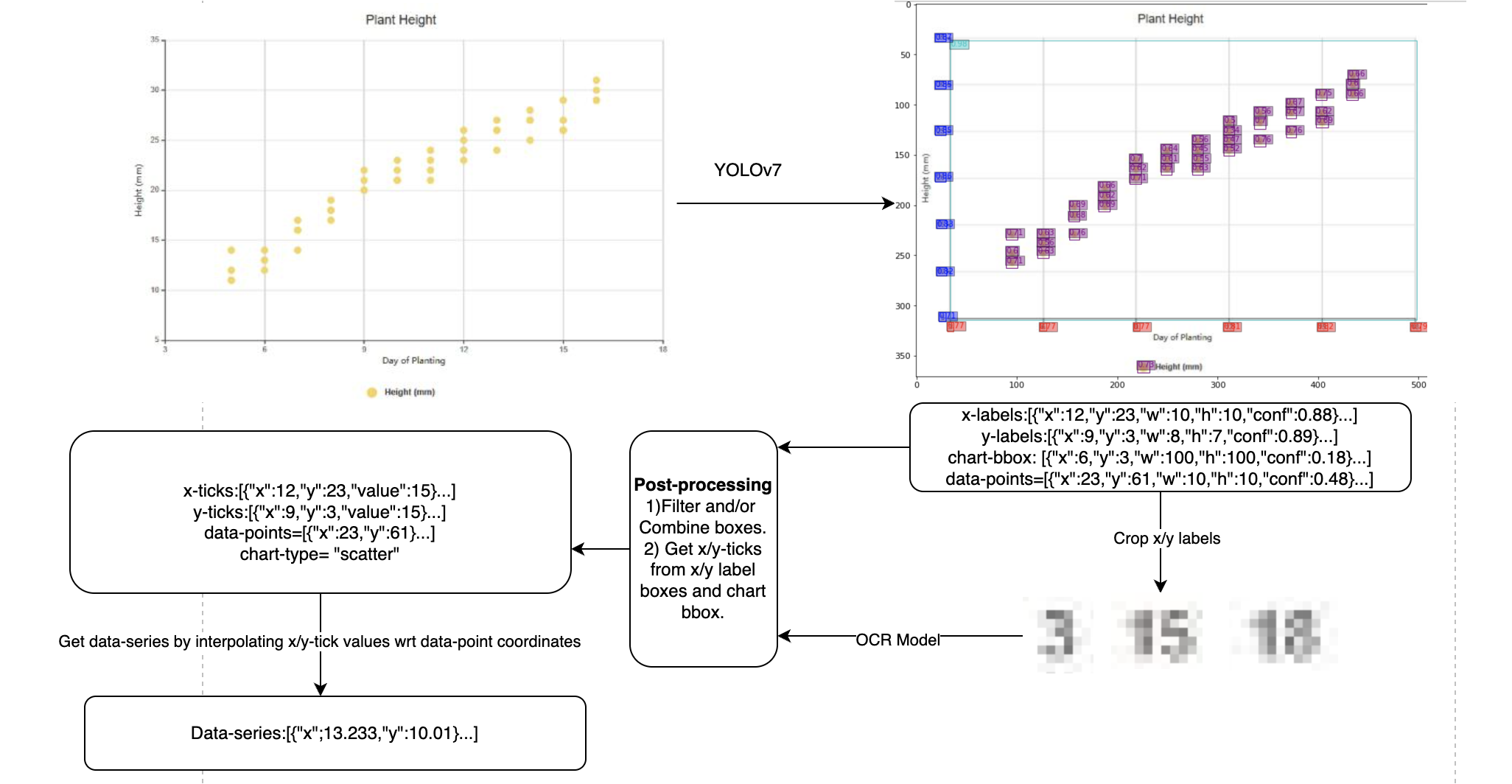
目标检测(YOLOv7-X)
我训练了一个YOLOv7模型来检测x轴标签、y轴标签、图表边界框以及图表上的数据点。数据点的坐标在数据集中并未提供。我通过对x轴和y轴刻度坐标相对于x轴/y轴标签(数值)进行线性插值,能够准确地计算出图表图像上数据点的位置。这里有一个使用这种方法创建数据集的笔记本。
在推理过程中,我通过将x轴和y轴标签的数值相对于数据点的坐标进行线性插值,来计算数据序列,从而反转了这一过程。
与其他方法(如Donut)相比,这种方法在散点图上也表现相对较好。
注意事项:
- 该目标检测模型也被用作图表类型分类模型。
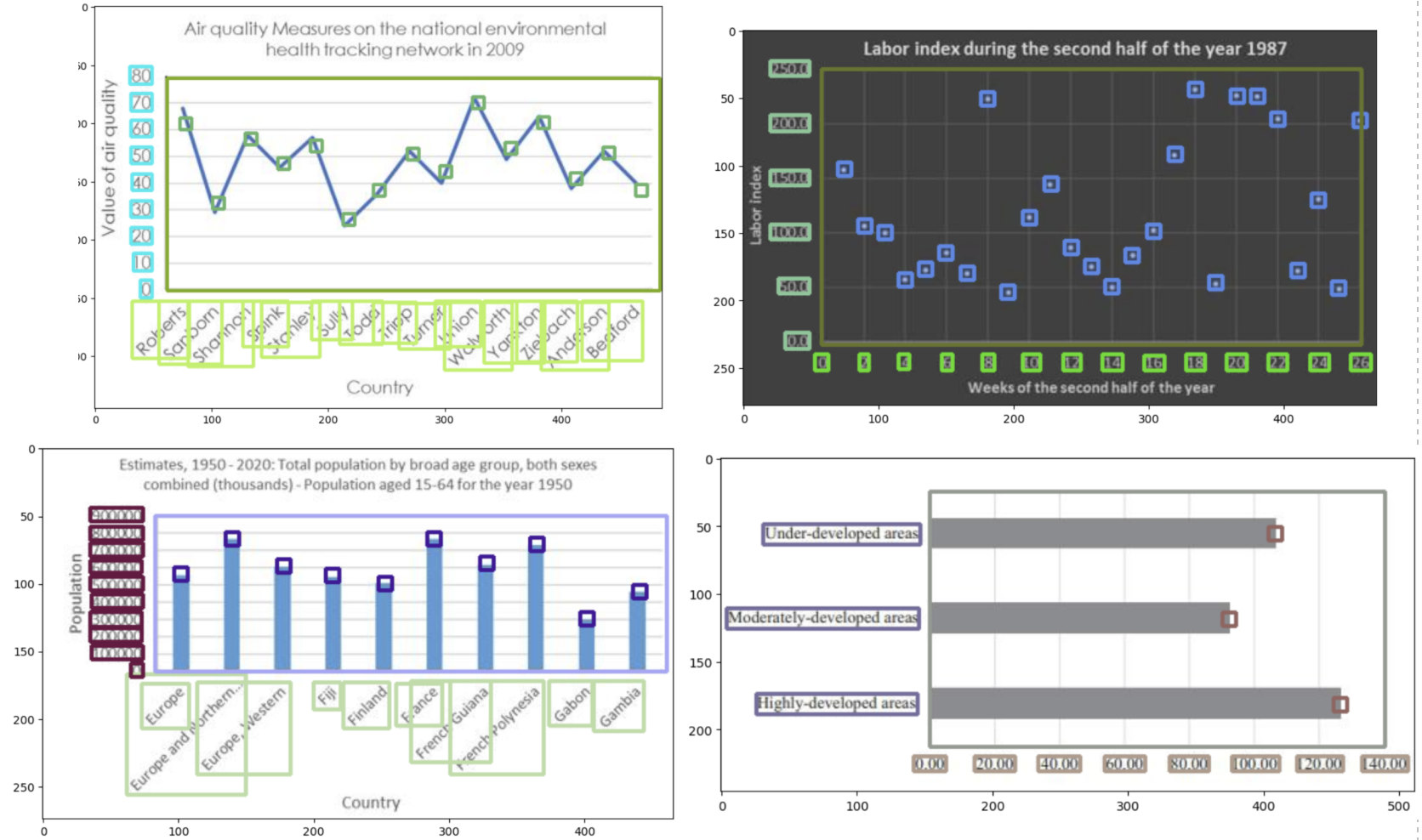
- 部分x轴标签存在重叠的边界框,如下图所示。然而,尽管输入图像包含邻近边界框的文本,我的OCR模型仍能够提取正确的文本。
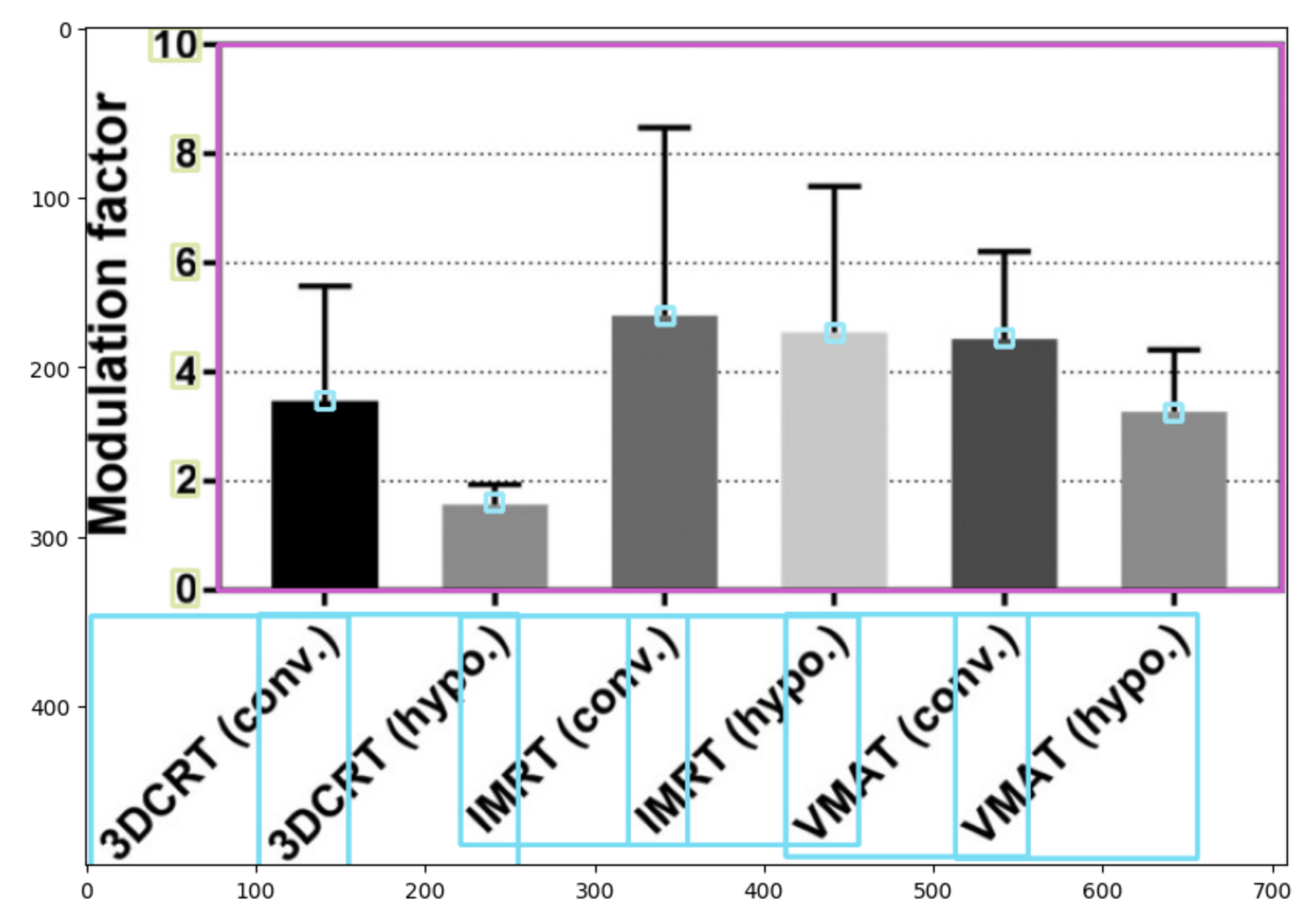
OCR模型
使用EasyOCR库,我训练了一个ResNet(特征提取器)+双向LSTM模型,并采用连接时序分类(CTC)损失。额外的数据集(ICPR 2022 CHART)使OCR模型的准确率从84%提升至89%,提高了约5%。我使用了这个笔记本作为训练OCR模型的起点(感谢@nadhirhasan)。
后处理
在获得模型的边界框后,我基于一些简单启发式方法进行后处理:移除位于图表边界框外的数据点,限制x轴标签(水平条形图为y轴标签)位于图表边界框下方,限制y轴标签(水平条形图为x轴标签)位于图表边界框左侧。此外,x/y轴刻度坐标是通过x/y轴边界框和图表边界框计算得出的。我使用x/y轴标签边界框中心到图表边界框上最近点的距离作为相应的x/y轴刻度坐标。我选择这种方法是因为在旧版模型中,x/y轴标签的精确率和召回率高于x/y轴刻度。
我只在竞赛的最后4周才参与进来。因此,由于时间不足,我无法尝试其他方法,如Donut。我认为这个模型还有很大的改进空间。例如,由于预测数量不匹配,模型做出的预测中约有25%会自动得分为0。这种不匹配是由于除散点图外,其他类型的图表只有1或2个数据点。